初学者入门手册-汇编语言浓缩教程
1、所有电脑语言写出的程序运行时在内存中都以机器码方式存储,机器码可以被比较准确的翻译成汇编语言,这是因为汇编语言兼容性最好,故几乎所有跟踪、调试工具(包括WIN95/98下)都是以汇编示人的,如果阁下对CRACK颇感兴趣……;
2、汇编直接与硬件打交道,如果你想搞通程序在执行时在电脑中的来龙去脉,也就是搞清电脑每个组成部分究竟在干什么、究竟怎么干?一个真正的硬件发烧友,不懂这些可不行。
对初学者而言,汇编的许多命令太复杂,往往学习很长时间也写不出一个漂漂亮亮的程序,以致妨碍了我们学习汇编的兴趣,不少人就此放弃。所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样)。某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了。为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ……)。但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP、WINRAR…依次压迫,嘿嘿!)教程。大言不惭的说,看通本文,你完全可以“不经意”间在前辈或是后生卖弄一下DEBUG,很有成就感的,试试看!那么――这个接下来呢?―― Here we go!(阅读时看不懂不要紧,下文必有分解)
因为汇编是通过CPU和内存跟硬件对话的,所以我们不得不先了解一下CPU和内存:(关于数的进制问题在此不提)
CPU是可以执行电脑所有算术╱逻辑运算与基本 I/O 控制功能的一块芯片。一种汇编语言只能用于特定的CPU。也就是说,不同的CPU其汇编语言的指令语法亦不相同。个人电脑由1981年推出至今,其CPU发展过程为:8086→80286→80386→80486→PENTIUM →……,还有AMD、CYRIX等旁支。后面兼容前面CPU的功能,只不过多了些指令(如多能奔腾的MMX指令集)、增大了寄存器(如386的32位EAX)、增多了寄存器(如486的FS)。为确保汇编程序可以适用于各种机型,所以推荐使用8086汇编语言,其兼容性最佳。本文所提均为8086汇编语言。寄存器(Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。用途:1.可将寄存器内的数据执行算术及逻辑运算。2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。3.可以用来读写数据到电脑的周边设备。8086 有8个8位数据寄存器,这些8位寄存器可分别组成16位寄存器:AH&AL=AX:累加寄存器,常用于运算;BH&BL=BX:基址寄存器,常用于地址索引;CH&CL=CX:计数寄存器,常用于计数;DH&DL=DX:数据寄存器,常用于数据传递。为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器 CS,DS,SS 来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。 所以,程序和其数据组合起来的大小,限制在DS 所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。除了前面所提的寄存器外,还有一些特殊功能的寄存器:IP(Intruction Pointer):指令指针寄存器,与CS配合使用,可跟踪程序的执行过程;SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置。BP(Base Pointer):基址指针寄存器,可用作SS的一个相对基址位置;SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针;DI(Destination Index):目的变址寄存器,可用来存放相对于 ES 段之目的变址指针。还有一个标志寄存器FR(Flag Register),有九个有意义的标志,将在下文用到时详细说明。
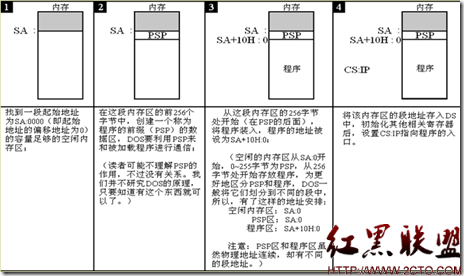
内存是电脑运作中的关键部分,也是电脑在工作中储存信息的地方。内存组织有许多可存放数值的储存位置,叫“地址”。8086地址总线有20位,所以CPU拥有达1M的寻址空间,这也是DOS的有效控制范围,而8086能做的运算仅限于处理16位数据,即只有0到64K,所以,必须用分段寻址才能控制整个内存地址。完整的20位地址可分成两部份:1.段基址(Segment):16位二进制数后面加上四个二进制0,即一个16进制0,变成20位二进制数,可设定1M中任何一个64K段,通常记做16位二进制数;2.偏移量(Offset):直接使用16位二进制数,指向段基址中的任何一个地址。如:2222(段基址):3333(偏移量),其实际的20位地址值为:25553。除了上述营养要充分吸收外,你还要知道什么是DOS、BIOS功能调用,简单的说,功能调用类似于WIN95 API,相当于子程序。汇编写程序已经够要命了,如果不用MS、IBM的子程序,这日子真是没法过了(关于功能调用详见《电脑爱好者》98年11期)。
编写汇编语言有两种主要的方法:
1.使用MASM或TASM等编译器;2.使用除错程序DEBUG.COM。DEBUG其实并不能算是一个编译器,它的主要用途在于除错,即修正汇编程序中的错误。不过,也可以用来写短的汇编程序,尤其对初学者而言,DEBUG 更是最佳的入门工具。因为DEBUG操作容易:只要键入DEBUG回车,A回车即可进行汇编,过程简单,而使用编译器时,必须用到文本编辑器、编译器本身、LINK以及EXE2BIN等程序,其中每一个程序都必须用到一系列相当复杂的命令才能工作,而且用编译器处理源程序,必须加入许多与指令语句无关的指示性语句,以供编译器识别,使用 DEBUG 可以避免一开始就碰到许多难以理解的程序行。DEBUG 除了能够汇编程序之外,还可用来检查和修改内存位置、载入储存和执行程序、以及检查和修改寄存器,换句话说,DEBUG是为了让我们接触硬件而设计的。(8086常用指令用法将在每个汇编程序中讲解,限于篇幅,不可能将所有指令列出)。
DEBUG的的A命令可以汇编出简单的COM文件,所以DEBUG编写的程序一定要由地址 100h(COM文件要求)开始才合法。FOLLOW ME,SETP BY SETP(步步回车):
输入 A100 ; 从DS:100开始汇编
2.输入 MOV DL,1 ; 将数值 01h 装入 DL 寄存器
3.输入 MOV AH,2 ; 将数值 02h 装入 DL 寄存器
4.输入 INT 21 ; 调用DOS 21号中断2号功能,用来逐个显示装入DL的字符
5.输入 INT 20 ; 调用DOS 20号中断,终止程序,将控制权交回给 DEBUG
6.请按 Enter 键
7.现在已将汇编语言程序放入内存中了,输入 G(运行)
8.出现结果:输出一个符号。
ㄖ ←输出结果其实不是它,因WORD97无法显示原结果,故找一赝品将就着。
Program terminated normally
我们可以用U命令将十六进制的机器码反汇编(Unassemble)成汇编指令。你将发现每一行右边的汇编指令就是被汇编成相应的机器码,而8086实际上就是以机器码来执行程序。
1.输入 U100,106
1FED:0100 B201 MOV DL,01
1FED:0102 B402 MOV AH,02
1FED:0104 CD21 INT 21
1FED:0106 CD20 INT 20
DEBUG可以用R命令来查看、改变寄存器内容。CS:IP寄存器,保存了将执行指令地址。
1.输入R
AX=0000 BX=0000 CX=0000 DX=0000 SP=FFEE BP=0000 SI=0000 DI=0000
DS=1FED ES=1FED SS=1FED CS=1FED IP=0100 NV UP EI PL NZ NA PO NC
1FED:0100 B201 MOV DL,01
当程序由DS:100开始执行,那么终止程序时,DEBUG会自动将IP内容重新设定为100。当你要将此程序做成一个独立的可执行文件,则可以用N命令对该程序命名。但一定要为COM文件,否则无法以DEBUG载入。
输入N SMILE.COM ;我们得告诉DEBUG程序长度:程序从100开始到106,故占用7
;字节。我们利用BX存放长度值高位部分,而以CX存放低位部分。
2.输入RBX ;查看 BX 寄存器的内容,本程序只有7个字节,故本步可省略
3.输入 RCX ;查看 CX 寄存器的内容
4.输入 7 ;程序的字节数
5.输入 W ;用W命令将该程序写入(Write)磁盘中
修行至此,我们便可以真正接触8086汇编指令了。 当我们写汇编语言程序的时候,通常不会直接将机器码放入内存中,而是打入一串助记符号(Mnemonic Symbols),这些符号比十六进制机器码更容易记住,此之谓汇编指令。助记符号,告诉CPU应执行何种运算。 也就是说,助忆符号所构成的汇编语言是为人设计的,而机器语言是对PC设计的。
现在,我们再来剖析一个可以将所有ASCII码显示出来的程序。
1. 输入 DEBUG
2. 输入 A100
3.输入 MOV CX,0100 ;装入循环次数
MOV DL,00 ;装入第一个ASCII码,随后每次循环装入新码
MOV AH,02
INT 21
INC DL ;INC:递增指令,每次将数据寄存器 DL 内的数值加 1
LOOP 0105 ;LOOP:循环指令,每执行一次LOOP,CX值减1,并跳
;到循环的起始地址105,直到CX为0,循环停止
INT 20
4.输入 G即可显示所有ASCII码
当我们想任意显示字符串,如:UNDERSTAND?,则可以使用DOS21H号中断9H号功能。输入下行程序,存盘并执行看看:
1.输入 A100
MOV DX,109 ;DS:DX = 字符串的起始地址
MOV AH,9 ;DOS的09h功能调用
INT 21 ;字符串输出
INT 20
DB 'UNDERSTAND?$';定义字符串
在汇编语言中,有两种不同的指令:1.正规指令:如 MOV 等,是属于CPU的指令,用来告诉CPU在程序执行时应做些什么,所以它会以运算码(OP-code)的方式存入内存中;2.伪指令:如DB等,是属于DEBUG等编译器的指令,用来告诉编译器在编译时应做些什么。DB(Define Byte)指令用来告诉DEBUG 将单引号内的所有ASCII 码放入内存中。使用 9H 功能的字符串必须以$结尾。用D命令可用来查看DB伪指令将那些内容放入内存。
6.输入 D100
1975:0100 BA 09 01 B4 09 CD 21 CD-20 75 6E 64 65 72 73 74 ......!. underst
1975:0110 61 6E 64 24 8B 46 F8 89-45 04 8B 46 34 00 64 19 and$.F..E..F4.d.
1975:0120 89 45 02 33 C0 5E 5F C9-C3 00 C8 04 00 00 57 56 .E.3.^_.......WV
1975:0130 6B F8 0E 81 C7 FE 53 8B-DF 8B C2 E8 32 FE 0B C0 k.....S.....2...
1975:0140 74 05 33 C0 99 EB 17 8B-45 0C E8 D4 97 8B F0 89 t.3.....E.......
1975:0150 56 FE 0B D0 74 EC 8B 45-08 03 C6 8B 56 FE 5E 5F V...t..E....V.^_
1975:0160 C9 C3 C8 02 00 00 6B D8-0E 81 C3 FE 53 89 5E FE ......k.....S.^.
1975:0170 8B C2 E8 FB FD 0B C0 75-09 8B 5E FE 8B 47 0C E8 .......u..^..G..
现在,我们来剖析另一个程序:由键盘输入任意字符串,然后显示出来。db 20指示DEBUG保留20h个未用的内存空间供缓冲区使用。
输入A100
MOV DX,0116 ;DS:DX = 缓冲区地址,由DB伪指令确定缓冲区地址
MOV AH,0A ;0Ah 号功能调用
INT 21 ;键盘输入缓冲区
MOV DL,0A ;由于功能Ah在每个字符串最后加一个归位码(0Dh由 Enter
MOV AH,02 ;产生),使光标自动回到输入行的最前端,为了使新输出的
INT 21 ;字符串不会盖掉原来输入的字符串,所以利用功能2h加一
;个换行码(OAh),使得光标移到下一行的的最前端。
MOV DX,0118 ;装入字符串的起始位置
MOV AH,09 ;9h功能遇到$符号才会停止输出,故字符串最后必须加上
INT 21 ;$,否则9h功能会继续将内存中的无用数据胡乱显示出来
INT 20
DB 20 ;定义缓冲区
送你一句话:学汇编切忌心浮气燥。
客套话就不讲了。工欲善其事,必先利其器。与其说DEBUG 是编译器,倒不如说它是“直译器”,DEBUG的A命令只可将一行汇编指令转成机器语言,且立刻执行。真正编译器(MASM)的运作是利用文本编辑器(EDIT等)将汇编指令建成一个独立且附加名为.ASM的文本文件,称源程序。它是MASM 程序的输入部分。MASM将输入的ASM文件,编译成.OBJ文件,称为目标程序。OBJ文件仅包含有关程序各部份要载入何处及如何与其他程序合并的信息,无法直接载入内存执行。链结程序LINK则可将OBJ文件转换成可载入内存执行(EXEcute)的EXE文件。还可以用EXE2BIN,将符合条件的EXE文件转成COM文件(COM 文件不但占用的内存最少,而且运行速度最快)。
下面我们用MASM写一个与用DEBUG写的第一个程序功能一样的程序。
用EDIT编辑一个SMILE.ASM的源程序文件。
源程序 DEBUG 程序
prognam segment
assume cs:prognam
org 100h A100
mov dl,1 mov dl,1
mov ah,2 mov ah,2
int 21h int 21
int 20h int 20
prognam ends
end
比较一下:1.因为MASM会将所有的数值假设为十进制,而DEBUG则只使用十六进制,所以在源程序中,我们必须在有关数字后加上代表进制的字母,如H代表十六进制,D代表十进制。若是以字母开头的十六进制数字,还必须在字母前加个0,以表示它是数,如0AH。2.源程序增加五行叙述:prognam segment 与 prognam ends 是成对的,用来告诉 MASM 及LINK,此程序将放在一个称为PROGNAM(PROGram NAMe)的程序段内,其中段名(PROGNAM)可以任取,但其位置必须固定。assume cs:prognam 必须在程序的开头,用来告诉编译器此程序所在段的位置放在CS寄存器中。end用来告诉MASM,程序到此结束, ORG 100H作用相当于DEBUG的A100,从偏移量100开始汇编。COM 文件的所有源程序都必须包含这五行,且必须依相同的次序及位置出现,这点东西记下就行,千篇一律。接着,我们用MASM编译SMILE.ASM。
输入 MASM SMILE ←不用打入附加名.ASM。
Microsoft (R) Macro Assembler Version 5.10
Copyright (C) Microsoft Corp 1981, 1988. All rights reserved.
Object filename [SMILE.OBJ]: ←是否改动输出OBJ文件名,如不改就ENTER
Source listing [NUL.LST]: ← 是否需要列表文件(LST),不需要就ENTER
Cross-reference [NUL.CRF]: ←是否需要对照文件(CRF),不需要则ENTER
50162 + 403867 Bytes symbol space free
0 Warning Errors ←警告错误,表示编译器对某些语句不理解,通常是输入错误。
0 Severe Errors ←严重错误,会造成程序无法执行,通常是语法结构错误。
如果没有一个错误存在,即可生成OBJ文件。OBJ中包含的是编译后的二进制结果,它还无法被 DOS载入内存中加以执行,必须加以链结(Linking)。以LINK将OBJ文件(SMILE.OBJ)链结成 EXE 文件(SMILE.EXE)时,。
1.输入 LINK SMILE ←不用附加名OBJ
Microsoft (R) Overlay Linker Version 3.64
Copyright (C) Microsoft Corp 1981, 1988. All rights reserved.
Run File [SMILE.EXE]: ← 是否改动输出EXE文件名,如不改就ENTER
List File [NUL.MAP]: ← 是否需要列表文件(MAP),不需要则ENTER
Libraries [.LIB]: ←是否需要库文件,要就键入文件名,不要则ENTER
LINK : warning L4021: no stack segment← 由于COM文件不使用堆栈段,所以错误信息
←"no stack segment"并不影响程序正常执行
至此已经生成EXE文件,我们还须使用EXE2BIN 将EXE文件(SMILE.EXE),转换成COM文件(SMILE.COM)。输入EXE2BIN SMILE产生 BIN 文件(SMILE.BIN)。其实 BIN 文件与 COM 文件是完全相同的,但由于DOS只认COM、EXE及BAT文件,所以BIN文件无法被正确执行,改名或直接输入 EXE2BIN SMILE SMILE.COM即可。现在,磁盘上应该有 SMILE.COM 文件了,你只要在提示符号C:>下,直接输入文件名称 SMILE ,就可以执行这个程序了。
你是否觉得用编译器产生程序的方法,比 DEBUG 麻烦多了!以小程序而言,的确是如此,但对于较大的程序,你就会发现其优点了。我们再将ASCII程序以编译器方式再做一次,看看有无差异。首先,用EDIT.COM建立 ASCII.ASM 文件。
prognam segment ;定义段
assume cs:prognam ;把上面定义段的段基址放入 CS
mov cx,100h ; 装入循环次数
mov dl,0 ; 装入第一个ASCII码,随后每次循环装入新码
next: mov ah,2
int 21h
inc dl ;INC:递增指令,每次将数据寄存器 DL 内的数值加 1
loop next ; 循环指令,执行一次,CX减1,直到CX为0,循环停止
int 20h
prognam ends ;段终止
end ;汇编终止
在汇编语言的源程序中,每一个程序行都包含三项元素:
start: mov dl,1 ;装入第一个ASCII码,随后每次循环装入新码
标识符 表达式 注解
在原始文件中加上注解可使程序更易理解,便于以后参考。每行注解以“;”与程序行分离。编译器对注解不予理会,注解的数据不会出现在OBJ、EXE或COM文件中。由于我们在写源程序时,并不知道每一程序行的地址,所以必须以符号名称来代表相对地址,称为“标识符”。我们通常在适当行的适当位置上,键入标识符。标识符(label)最长可达31 个字节,因此我们在程序中,尽量以简洁的文字做为标识符。现在,你可以将此ASCII.ASM 文件编译成 ASCII.COM 了。1.MASM ASCII,2.LINK ASCII,3.EXE2BIN ASCII ASCII.COM。
注意:当你以编译器汇编你设计的程序时,常会发生打字错误、标识符名称拼错、十六进制数少了h、逻辑错误等。汇编老手常给新人的忠告是:最好料到自己所写的程序一定会有些错误(别人告诉我的);如果第一次执行程序后,就得到期望的结果,你最好还是在检查一遍,因为它可能是错的。原则上,只要大体的逻辑架构正确,查找程序中错误的过程,与写程序本身相比甚至更有意思。写大程序时,最好能分成许多模块,如此可使程序本身的目的较单纯,易于撰写与查错,另外也可让程序中不同部份之间的界限较清楚,节省编译的时间。如果读程序有读不懂的地方最好用纸笔记下有关寄存器、内存等内容,在纸上慢慢比划,就豁然开朗了。 下面我们将写一个能从键盘取得一个十进制的数值,并将其转换成十六进制数值而显示于屏幕上的“大程序”。前言:要让8086执行这样的功能,我们必须先将此问题分解成一连串的步骤,称为程序规划。首先,以流程图的方式,来确保整个程序在逻辑上没有问题(不用说了吧!什么语言都要有此步骤)。这种模块化的规划方式,称之为“由上而下的程序规划”。而在真正写程序时,却是从最小的单位模块(子程序)开始,当每个模块都完成之后,再合并成大程序;这种大处著眼,小处著手的方式称为“由下而上的程序设计”。
我们的第一个模块是BINIHEX,其主要用途是从8086的BX寄存器中取出二进制数,并以十六进制方式显示在屏幕上。注意:子程序如不能独立运行,实属正常。
binihex segment
assume cs:binihex
mov ch,4 ;记录转换后的十六进制位数(四位)
rotate: mov cl,4 ;利用CL当计数器,记录寄存器数位移动次数
rol bx,cl ;循环寄存器BX的内容,以便依序处理4个十六进制数
mov al,bl ;把bx低八位bl内数据转移至al
and al,0fh ;把无用位清零
add al,30h ;把AL内数据加30H,并存入al
cmp al,3ah ;与3ah比较
jl printit ;小于3ah则转移
add al,7h ;把AL内数据加30H,并存入al
printit:mov dl,al ;把ASCII码装入DL
mov ah,2
int 21h
dec ch ;ch减一,减到零时,零标志置1
jnz rotate ;JNZ:当零标志未置1,则跳到指定地址。即:不等,则转移
int 20h ;从子程序退回主程序
binihex ends
end
利用循环左移指令ROL循环寄存器BX(BX内容将由第二个子程序提供)的内容,以便依序处理4个十六进制数:1. 利用CL当计数器,记录寄存器移位的次数。2.将BX的第一个十六进制值移到最右边。利用 AND (逻辑“与”运算:对应位都为1时,其结果为1,其余情况为零)把不要的部份清零,得到结果:先将BL值存入AL中,再利用AND以0Fh(00001111)将AL的左边四位清零。由于0到9的ASCII码为30h到39h,而A到F之ASCII码为41h到46h,间断了7h,所以得到结果:若AL之内容小于3Ah,则AL值只加30h,否则AL再加7h。ADD指令会将两个表达式相加,其结果存于左边表达式内。标志寄存器(Flag Register)是一个单独的十六位寄存器,有9个标志位,某些汇编指令(大部份是涉及比较、算术或逻辑运算的指令)执行时,会将相关标志位置1或清0, 常碰到的标志位有零标志(ZF)、符号标志(SF)、溢出标志(OF)和进位标志(CF)。 标志位保存了某个指令执行后对它的影响,可用其他相关指令,查出标志的状态,根据状态产生动作。CMP指令很像减法,是将两个表达式的值相减,但寄存器或内存的内容并未改变,只是相对的标志位发生改变而已:若 AL 值小于 3Ah,则正负号标志位会置0,反之则置1。 JL指令可解释为:小于就转移到指定位置,大于、等于则向下执行。CMP和JG 、JL等条件转移指令一起使用,可以形成程序的分支结构,是写汇编程序常用技巧。
第二个模块DECIBIN 用来接收键盘打入的十进制数,并将它转换成二进制数放于BX 寄存器中,供模块1 BINIHEX使用。
decibin segment
assume cs:decibin
mov bx,0 ;BX清零
newchar:mov ah,1 ;
int 21h ;读一个键盘输入符号入al,并显示
sub al,30h ;al减去30H,结果存于al中,完成ASCII码转二进制码
jl exit ;小于零则转移
cmp al,9d
jg exit ;左>右则转移
cbw ;8位al转换成16位ax
xchg ax,bx ;互换ax和bx内数据
mov cx,10d ;十进制数10入cx
mul cx ;表达式的值与ax内容相乘,并将结果存于ax
xchg ax,bx
add bx,ax
jmp newchar ;无条件转移
exit: int 20 ;回主程序
decibin ends
end
CBW 实际结果是:若AL中的值为正,则AH填入00h;反之,则AH填入FFh。XCHG常用于需要暂时保留某个寄存器中的内容时。
当然,还得一个子程序(CRLF)使后显示的十六进制数不会盖掉先输入的十进制数。
crlf segment
assume cs:crlf
mov dl,0dh ;回车的ASCII码0DH入DL
mov ah,2
int 21h
mov dl,0ah ;换行的ASSII码0AH入AH
mov ah,2
int 21h
int 20 ;回主程序
crlf ends
end
现在我们就可以将BINIHEX、DECIBIN及CRLF等模块合并成一个大程序了。首先,我们要将这三个模块子程序略加改动。然后,再写一段程序来调用每一个子程序。
crlf proc near;
mov dl,0dh
mov ah,2
int 21h
mov dl,0ah
mov ah,2
int 21h
ret
crlf endp
类似SEGMENT与ENDS的伪指令,PROC与ENDP也是成对出现,用来识别并定义一个程序。其实,PROC 真正的作用只是告诉编译器:所调用的程序是属于近程(NEAR)或远程(FAR)。 一般的程序是由 DEBUG 直接调用的,所以用 INT 20 返回,用 CALL 指令所调用的程序则改用返回指令RET,RET会把控制权转移到栈顶所指的地址,而该地址是由调用此程序的 CALL指令所放入的。
各模块都搞定了,然后我们把子程序组合起来就大功告成
decihex segment ;主程序
assume cs:decihex
org 100h
mov cx,4 ;循环次数入cx;由于子程序要用到cx,故子程序要将cx入栈
repeat: call decibin;调用十进制转二进制子程序
call crlf ;调用添加回、换行符子程序
call binihex ;调用二进制转十六进制并显示子程序
call crlf
loop repeat ;循环4次,可连续运算4次
mov ah,4ch ; 调用DOS21号中断4c号功能,退出程序,作用跟INT 20H
int 21H ; 一样,但适用面更广,INT20H退不出时,试一下它
decibin proc near push cx ;将cx压入堆栈,;
┇ exit: pop cx ;将cx还原; retdecibin endp binihex proc near push cx
┇ pop cx retbinihex endp crlf proc near
push cx
┇ pop cx retcrlf endpdecihex ends end
CALL指令用来调用子程序,并将控制权转移到子程序地址,同时将CALL的下行一指令地址定为返回地址,并压入堆栈中。CALL 可分为近程(NEAR)及远程(FAR)两种:1.NEAR:IP的内容被压入堆栈中,用于程序与程序在同一段中。2.FAR:CS 、IP寄存器的内容依次压入堆栈中,用于程序与程序在不同段中。PUSH、POP又是一对指令用于将寄存器内容压入、弹出,用来保护寄存器数据,子程序调用中运用较多。堆栈指针有个“后进先出”原则,像PUSH AX,PUSH BX…POP BX,POP AX这样才能作到保护数据丝毫不差。
到此为止汇编语言超浓缩教程就结束了,希望对你学习汇编语言起到很大的帮助。
爱电脑 就爱www.zzzyk.com 电脑知识网