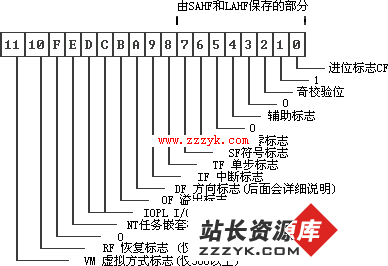
x86汇编语言教程学习之第三节
2.2 使用寄存器
在前一节中的x86基本寄存器的介绍,对于一个汇编语言编程人员来说是不可或缺的。现在你知道,寄存器是处理器内部的一些保存数据的存储单元。仅仅了解这些是不足以写出一个可用的汇编语言程序的,但你已经可以大致读懂一般汇编语言程序了(不必惊讶,因为汇编语言的祝记符和英文单词非常接近),因为你已经了解了关于基本寄存器的绝大多数知识。
在正式引入第一个汇编语言程序之前,我粗略地介绍一下汇编语言中不同进制整数的表示方法。如果你不了解十进制以外的其他进制,请把鼠标移动到这里。
数字计算机内部只支持二进制数,因为这样计算机只需要表示两种(某些情况是3种,这一内容超过了这份教程的范围,如果您感兴趣,可以参考数字逻辑电路的相关书籍)状态. 对于电路而言,这表现为高、低电平,或者开、关,分别非常明显,因而工作比较稳定;另一方面,由于只有两种状态,设计起来也比较简单。这样,使用二进制意味着低成本、稳定,多数情况下,这也意味着快速。
与十进制类似,我们可以用下面的式子来换算出一个任意形如am-1……a3a2a1a0 的m位r进制数对应的数值n:
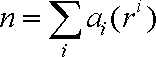
程序设计中常用十六进制和八进制数字代替二进制数,其原因在于,16和8是2的整次方幂,这样,一位十六或八进制数可以表示整数个二进制位。十六进制中,使用字母A、B、C、D、E、F表示10-15,而十六进制或八进制数制表示的的数字比二进制数更短一些。
EAX的内容为000A3412h.
汇编语言中的整数常量表示
十进制整数
这是汇编器默认的数制。直接用我们熟悉的表示方式表示即可。例如,1234表示十进制的1234。不过,如果你指定了使用其他数制,或者有凡事都进行完整定义的小爱好,也可以写成[十进制数]d或[十进制数]D的形式。
十六进制数
这是汇编程序中最常用的数制,我个人比较偏爱使用十六进制表示数据,至于为什么,以后我会作说明。十六进制数表示为0[十六进制数]h或0[十六进制数]H,其中,如果十六进制数的第一位是数字,则开头的0可以省略。例如,7fffh, 0ffffh,等等。
二进制数
这也是一种常用的数制。二进制数表示为[二进制数]b或[二进制数]B。一般程序中用二进制数表示掩码(mask code)等数据非常的直观,但需要些很长的数据(4位二进制数相当于一位十六进制数)。例如,1010110b。
八进制数
八进制数现在已经不是很常用了(确实还在用,一个典型的例子是Unix的文件属性)。八进制数的形式是[八进制数]q、[八进制数]Q、[八进制数]o、[八进制数]O。例如,777Q。
需要说明的是,这些方法是针对宏汇编器(例如,MASM、TASM、NASM)说的,调试器默认使用十六进制表示整数,并且不需要特别的声明(例如,在调试器中直接用FFFF表示十进制的65535,用10表示十进制的16)。
现在我们来写一小段汇编程序,修改EAX、EBX、ECX、EDX的数值。
我们假定程序执行之前,寄存器中的数值是全0:
? X H L EAX 0000 00 00 EBX 0000 00 00 ECX 0000 00 00 EDX 0000 00 00
正如前面提到的,EAX的高16bit是没有办法直接访问的,而AX对应它的低16bit,AH、AL分别对应AX的高、低8bit。
mov eax, 012345678h
mov ebx, 0abcdeffeh
mov ecx, 1
mov edx, 2 ; 将012345678h送入eax
; 将0abcdeffeh送入ebx
; 将000000001h送入ecx
; 将000000002h送入edx
则执行上述程序段之后,寄存器的内容变为:
? X H L EAX 1234 56 78 EBX abcd ef fe ECX 0000 00 01 EDX 0000 00 02
那么,你已经了解了mov这个指令(mov是move的缩写)的一种用法。它可以将数送到寄存器中。我们来看看下面的代码:
mov eax, ebx
mov ecx, edx ; ebx内容送入eax
; edx内容送入ecx
则寄存器内容变为:
? X H L EAX abcd ef fe EBX abcd ef fe ECX 0000 00 02 EDX 0000 00 02
我们可以看到,“move”之后,数据依然保存在原来的寄存器中。不妨把mov指令理解为“送入”,或“装入”。
练习题
把寄存器恢复成都为全0的状态,然后执行下面的代码:
mov eax, 0a1234h
mov bx, ax
mov ah, bl
mov al, bh ; 将0a1234h送入eax
; 将ax的内容送入bx
; 将bl内容送入ah
; 将bh内容送入al
思考:此时,EAX的内容将是多少?[答案]
下面我们将介绍一些指令。在介绍指令之前,我们约定:
使用Intel文档中的寄存器表示方式
reg32 32-bit寄存器(表示EAX、EBX等) reg16 16-bit寄存器(在32位处理器中,这AX、BX等) reg8 8-bit寄存器(表示AL、BH等) imm32 32-bit立即数(可以理解为常数) imm16 16-bit立即数 imm8 8-bit立即数
在寄存器中载入另一寄存器,或立即数的值:
mov reg32, (reg32 | imm8 | imm16 | imm32)
mov reg32, (reg16 | imm8 | imm16)
mov reg8, (reg8 | imm8)
例如,mov eax, 010h表示,在eax中载入00000010h。需要注意的是,如果你希望在寄存器中装入0,则有一种更快的方法,在后面我们将提到。
交换寄存器的内容:
xchg reg32, reg32
xchg reg16, reg16
xchg reg8, reg8
例如,xchg ebx, ecx,则ebx与ecx的数值将被交换。由于系统提供了这个指令,因此,采用其他方法交换时,速度将会较慢,并需要占用更多的存储空间,编程时要避免这种情况,即,尽量利用系统提供的指令,因为多数情况下,这意味着更小、更快的代码,同时也杜绝了错误(如果说Intel的CPU在交换寄存器内容的时候也会出错,那么它就不用卖CPU了。而对于你来说,检查一行代码的正确性也显然比检查更多代码的正确性要容易)刚才的习题的程序用下面的代码将更有效:
mov eax, 0a1234h
mov bx, ax
xchg ah, al ; 将0a1234h送入eax
; 将ax内容送入bx
; 交换ah, al的内容
递增或递减寄存器的值:
inc reg(8,16,32)
dec reg(8,16,32)
这两个指令往往用于循环中对指针的操作。需要说明的是,某些时候我们有更好的方法来处理循环,例如使用loop指令,或rep前缀。这些将在后面的章节中介绍。
将寄存器的数值与另一寄存器,或立即数的值相加,并存回此寄存器:
add reg32, reg32 / imm(8,16,32)
add reg16, reg16 / imm(8,16)
add reg8, reg8 / imm(8)
例如,add eax, edx,将eax+edx的值存入eax。减法指令和加法类似,只是将add换成sub。
需要说明的是,与高级语言不同,汇编语言中,如果要计算两数之和(差、积、商,或一般地说,运算结果),那么必然有一个寄存器被用来保存结果。在PASCAL中,我们可以用nA := nB + nC来让nA保存nB+nC的结果,然而,汇编语言并不提供这种方法。如果你希望保持寄存器中的结果,需要用另外的指令。这也从另一个侧面反映了“寄存器”这个名字的意义。数据只是“寄存”在那里。如果你需要保存数据,那么需要将它放到内存或其他地方。
类似的指令还有and、or、xor(与,或,异或)等等。它们进行的是逻辑运算。
我们称add、mov、sub、and等称为为指令助记符(这么叫是因为它比机器语言容易记忆,而起作用就是方便人记忆,某些资料中也称为指令、操作码、opcode[operation code]等);后面的参数成为操作数,一个指令可以没有操作数,也可以有一两个操作数,通常有一个操作数的指令,这个操作数就是它的操作对象;而两个参数的指令,前一个操作数一般是保存操作结果的地方,而后一个是附加的参数。
我不打算在这份教程中用大量的篇幅介绍指令——很多人做得比我更好,而且指令本身并不是重点,如果你学会了如何组织语句,那么只要稍加学习就能轻易掌握其他指令。更多的指令可以参考Intel提供的资料。编写程序的时候,也可以参考一些在线参考手册。Tech!Help和HelpPC 2.10尽管已经很旧,但足以应付绝大多数需要。
聪明的读者也许已经发现,使用sub eax, eax,或者xor eax, eax,可以得到与mov eax, 0类似的效果。在高级语言中,你大概不会选择用a=a-a来给a赋值,因为测试会告诉你这么做更慢,简直就是在自找麻烦,然而在汇编语言中,你会得到相反的结论,多数情况下,以由快到慢的速度排列,这三条指令将是xor eax, eax、sub eax, eax和mov eax, 0。
为什么呢?处理器在执行指令时,需要经过几个不同的阶段:取指、译码、取数、执行。
我们反复强调,寄存器是CPU的一部分。从寄存器取数,其速度很显然要比从内存中取数快。那么,不难理解,xor eax, eax要比mov eax, 0更快一些。
那么,为什么a=a-a通常要比a=0慢一些呢?这和编译器的优化有一定关系。多数编译器会把a=a-a翻译成类似下面的代码(通常,高级语言通过ebp和偏移量来访问局部变量;程序中,x为a相对于本地堆的偏移量,在只包含一个32-bit整形变量的程序中,这个值通常是4):
mov eax, dword ptr [ebp-x]
sub eax, dword ptr [ebp-x]
mov dword ptr [ebp-x],eax
而把a=0翻译成
mov dword ptr [ebp-x], 0
上面的翻译只是示意性的,略去了很多必要的步骤,如保护寄存器内容、恢复等等。如果你对与编译程序的实现过程感兴趣,可以参考相应的书籍。多数编译器(特别是C/C++编译器,如Microsoft Visual C++)都提供了从源代码到宏汇编语言程序的附加编译输出选项。这种情况下,你可以很方便地了解编译程序执行的输出结果;如果编译程序没有提供这样的功能也没有关系,调试器会让你看到编译器的编译结果。
如果你明确地知道编译器编译出的结果不是最优的,那就可以着手用汇编语言来重写那段代码了。怎么确认是否应该用汇编语言重写呢?
使用汇编语言重写代码之前需要确认的几件事情
首先,这种优化最好有明显的效果。比如,一段循环中的计算,等等。一条语句的执行时间是很短的,现在新的CPU的指令周期都在0.000000001s以下,Intel甚至已经做出了4GHz主频(主频的倒数是时钟周期)的CPU,如果你的代码自始至终只执行一次,并且你只是减少了几个时钟周期的执行时间,那么改变将是无法让人察觉的;很多情况下,这种“优化”并不被提倡,尽管它确实减少了执行时间,但为此需要付出大量的时间、人力,多数情况下得不偿失(极端情况,比如你的设备内存价格非常昂贵的时候,这种优化也许会有意义)。 其次,确认你已经使用了最好的算法,并且,你优化的程序的实现是正确的。汇编语言能够提供同样算法的最快实现,然而,它并不是万金油,更不是解决一切的灵丹妙药。用高级语言实现一种好的算法,不一定会比汇编语言实现一种差的算法更慢。不过需要注意的是,时间、空间复杂度最小的算法不一定就是解决某一特定问题的最佳算法。举例说,快速排序在完全逆序的情况下等价于冒泡排序,这时其他方法就比它快。同时,用汇编语言优化一个不正确的算法实现,将给调试带来很大的麻烦。 最后,确认你已经将高级语言编译器的性能发挥到极致。Microsoft的编译器在RELEASE模式和DEBUG模式会有差异相当大的输出,而对于GNU系列的编译器而言,不同级别的优化也会生成几乎完全不同的代码。此外,在编程时对于问题的严格定义,可以极大地帮助编译器的优化过程。如何优化高级语言代码,使其编译结果最优超出了本教程的范围,但如果你不能确认已经发挥了编译器的最大效能,用汇编语言往往是一种更为费力的方法。 还有一点非常重要,那就是你明白自己做的是什么。好的高级语言编译器有时会有一些让人难以理解的行为,比如,重新排列指令顺序,等等。如果你发现这种情况,那么优化的时候就应该小心——编译器很可能比你拥有更多的关于处理器的知识,例如,对于一个超标量处理器,编译器会对指令序列进行“封包”,使他们尽可能的并行执行;此外,宏汇编器有时会自动插入一些nop指令,其作用是将指令凑成整数字长(32-bit,对于16-bit处理器,是16-bit)。这些都是提高代码性能的必要措施,如果你不了解处理器,那么最好不要改动编译器生成的代码,因为这种情况下,盲目的修改往往不会得到预期的效果。
曾经在一份杂志上看到过有人用纯机器语言编写程序。不清楚到底这是不是编辑的失误,因为一个头脑正常的人恐怕不会这么做程序,即使它不长、也不复杂。首先,汇编器能够完成某些封包操作,即使不行,也可以用db伪指令来写指令;用汇编语言写程序可以防止很多错误的发生,同时,它还减轻了人的负担,很显然,“完全用机器语言写程序”是完全没有必要的,因为汇编语言可以做出完全一样的事情,并且你可以依赖它,因为计算机不会出错,而人总有出错的时候。此外,如前面所言,如果用高级语言实现程序的代价不大(例如,这段代码在程序的整个执行过程中只执行一遍,并且,这一遍的执行时间也小于一秒),那么,为什么不用高级语言实现呢?
一些比较狂热的编程爱好者可能不太喜欢我的这种观点。比方说,他们可能希望精益求精地优化每一字节的代码。但多数情况下我们有更重要的事情,例如,你的算法是最优的吗?你已经把程序在高级语言许可的范围内优化到尽头了吗?并不是所有的人都有资格这样说。汇编语言是这样一件东西,它足够的强大,能够控制计算机,完成它能够实现的任何功能;同时,因为它的强大,也会提高开发成本,并且,难于维护。因此,我个人的建议是,如果在软件开发中使用汇编语言,则应在软件接近完成的时候使用,这样可以减少很多不必要的投入。
第二章中,我介绍了x86系列处理器的基本寄存器。这些寄存器对于x86兼容处理器仍然是有效的,如果你偏爱AMD的CPU,那么使用这些寄存器的程序同样也可以正常运行。
不过现在说用汇编语言进行优化还为时尚早——不可能写程序,而只操作这些寄存器,因为这样只能完成非常简单的操作,既然是简单的操作,那可能就会让人觉得乏味,甚至找一台足够快的机器穷举它的所有结果(如果可以穷举的话),并直接写程序调用,因为这样通常会更快。但话说回来,看完接下来的两章——内存和堆栈操作,你就可以独立完成几乎所有的任务了,配合第五章中断、第六章子程序的知识,你将知道如何驾驭处理器,并让它为你工作。
www.zzzyk.com电脑知识网,平板电脑知识也很精彩