LAC : The secret of ld2
这几个晚上(周末除外)都在分解Lingoes-Extractor作者的另外一个工程的代码, 同样是用于分析LD2文件的,但仅仅一个java文件就搞定了,对于我这样的JAVA初学者来说真是'太好了'...
从第一次找到Extractor的代码起,我就一直很怀疑这位作者要不跟Lingoes有点关系,要不就是一位真正的破解易做图...因为Extractor太完美了...代码不多,却非常清晰地标记并分解出了LD2的各个段的数据,以及数据间的关系...我的怀疑来自其对ld2文件格式的认识,每一段,每一个字节的意义都非常地准确地标示出来,更神奇的是那些'无从追踪'的魔数, 例如, 单词索引间隔固定为10, 14字节的索引数据块,等等...这些都是怎么推到出来的啊...
我对自己的怀疑更偏向于后者,因为通过查看作者的其他代码,其除了分解了ld2文件外,还包括其他多个词典的数据文件...(感到震惊的同学们,自己去围观吧...另,多说一句,googlecode.com是个好地方...)
我并不关心怀疑本身的答案, 因为我已经非常开心 --Extractor终让我有机会窥视到Lingoes的ld2文件的秘密...
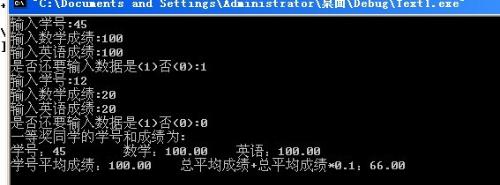
贴段代码, 以'奖励'自己多夜的敲敲打打...(是我写的Java代码,表认真啊...)
private static void getData(final int index) throws IOException {
RandomAccessFile file = new RandomAccessFile("output.data", "r");
final ByteBuffer buf = ByteBuffer.allocate((int) file.getChannel().size());
file.getChannel().read(buf);
buf.order(ByteOrder.LITTLE_ENDIAN);
int offset = 29;
final int idx[] = new int[6];//
getIndex(buf, offset * 10, idx);
if(idx[5] != idx[1]) {
Output("self xml = " + getXml(buf, idx[1], idx[5] - idx[1]));
}
if(idx[3] == 0) {
Output("word = " + getWord(buf, idx[0], idx[4] - idx[0]));
}
else {
int ref = idx[3];
int offsetword = idx[0];
final int lenword = idx[4] - idx[0];
while(ref -- > 0) {
offset = buf.getInt(lenInflatedWordsIndex + idx[0]);
getIndex(buf, offset * 10, idx);
Output("ref(" + offset + ") xml = " + getXml(buf, idx[1], idx[5] - idx[1]));
offsetword += 4;
}
Output("word = " + getWord(buf, offsetword, lenword));
}
file.close();
}
补充:软件开发 , C++ ,