抽象工厂——设计模式
一、了解抽象工厂设计模式书上说:提供一个创建一系列相关或相互依赖对象的接口,而无需制定他们具体的类。
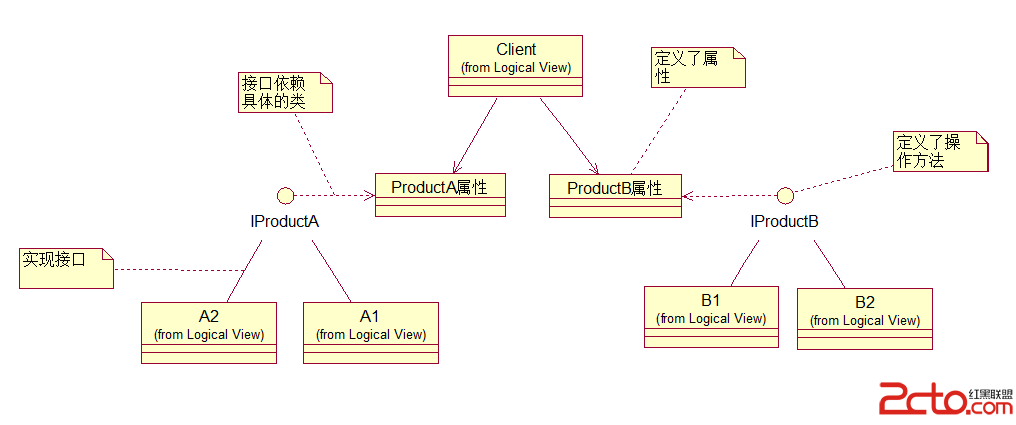
二、看类图

解说员:图上分两部分来看,一部分是左边的IFactory家族,另一部分是右边的IProduct 家族。
1、先看IProduct家族。
第一层:客户需求。可以看出我们需要哪些产品,由客户端决定,我们需要提前设计好第二层的产品。
第二层:ProductA和ProductB,这一系列的产品,具体要根据实际情况来确定。
第二层要说明的是:这个具体的产品的属性是不变的,而我们要对这个产品进行的各种操作是变化的,为了符合开放——封闭,和封装原则,在修改方法的时候不必影响到属性,我们把这个产品类分成了两部分,一部分是具体的名词类,不包含任何方法,只有该类的属性;另一部分是抽象接口:定义对该类的操作方法。这样我们就可以单独的对一个类的属性或者是方法进行分别操作,而互不影响,做到面向对象的封装。他们之间是依赖关系,接口依赖具体类。这个内部关系,在上图中没有变现出来。
也就是说,第三层实现的是第二层的接口方法,访问和操作的是第二层的具体类。
第三层:A1,A2,则是具体的实现类了。他们是ProductA 的具体实现过程。可能实现有多种,SO,具体的实现类也要多个,当然也需要一个统一的接口来统一管理。这里的接口就设在了第二层,有力第二层的接口,我们就可以在三层进行扩展,这也是一个封装。
体现的原则
开放——封闭原则:对扩展开放,对修改封闭。
在这个三层图上,有两个接口,也就是有两个地方可能发生变化,一个是数据库的选择,一个是访问数据库表的选择。
依赖倒转原则:抽象工厂的设计是由上自下逐步抽象的,且是针对接口编程,在最后一层才开始考虑具体的实现,提高了代码的复用,分别体现了:高层模块不依赖低层模块;抽象不依赖细节。
单一原则:第三层的每个类都是对单一功能的实现,对一个数据库表进行访问。
举例说明:用户需要访问数据库,那第二层就是数据库表,这些是哪个数据库都具备的;从第一层到二层扩展为了将来对更多或者其他数据库表的访问;现在我们要访问用户表,或许以后,我们还需要访问公司部门表,或者公司财务表;第三层应该考虑数据库的具体访问,操作实现,可扩展的子类有SQL server,Access 或者oracle。这些都是不同的实现过称,但同属于实现这一级别。可能现在用的是access,将来用SQL server,或者是Oracle,所以我们在要第二层为什么准备了接口,以备第三层的多种实现。
2、看IFactory家族。
此处工厂不是具体的制造产品的工厂,只是一个中介所。为什么这么说?
第一层:定义了一个创建一系列相关或相互依赖对象的接口。
例如我们需要访问的多个数据库表都在其中定义。这也是区别于工厂模式的一点。工厂模式针对的是一类,而抽象工厂针对的是一系列产品。
第二层:具体实现访问方法,他们根据客户端实例化的对象,帮助用户找到Iproduct 家族中第三层的地址,达到实现的目的。
练手:对SQL server和ACCESS两种数据库中的用户表和部门表进行访问。
[csharp]
//定义用户表类——定义了用户表的属性
class User
{
private int id;
public int ID
{
get { return id; }
set { id = value; }
}
private string name;
public string Name
{
get { return name; }
set { name = value; }
}
}
//定义数据库用户表接口——定义了对用户表的进行的操作
inte易做图ce IUser
{
void Insert(User user);
User GetUser(int id);
}
//定义SQL数据库表
class SqlserverUser:IUser
{
public void Insert(User user)
{
Console.WriteLine("在SQL 中增加一条用户记录");
}
public User GetUser(int id)
{
Console.WriteLine("在SQL 中根据ID得到一条用户记录");
return null;
}
}
//定义Access数据库表
class AccessUser : IUser
{
public void Insert(User user)
{
Console.WriteLine("在Access 中增加一条用户记录");
}
public User GetUser(int id)
{
Console.WriteLine("在Access 中根据ID得到一条用户记录");
return null;
}
}
&nbs
补充:软件开发 , C# ,