白话算法(3) 哥就是这么自信
据有关砖家说每天YY几次有益身心健康,所以让我们来练习一下:如果有一天我们也发明了个什么算法,叫什么名字好呢?
不如先参考一下前辈们都是怎么做的。
1)根据物理特性或实现方法命名:插入排序、归并排序、二分查找、螺旋丸、易做图术(天杀的,这个居然是易做图忍术);
2)以发明者名字命名:希尔排序、霍夫曼编码、高斯消去法、Linux;
3)用单词首字母组合命名:SUN(Standford Unix Networks,啧啧,一看就是纯技术公司,以后我要是开公司就叫 CRUD & HTML & Information & NewTech & ASP & .Net & BS——CHINA.NB)、IBM(International Business Machines Corporation)、UNIX(Uniplexed Information and Computering System);
4)借用地名、动物名以及各种八杆子打不着的东西的名字:东芝(东京芝浦电气株式会社)、小天鹅、苹果、Oracle(神谕、预言)、NIKE(希腊胜利女神的名字)、Java、python、.net(说实话每次去Google的时候都不知到应该搜“.net”还是“dotnet”,见过无厘头的);
5)诗意型:美的、Hibernate、月读、红黑树(为什么不叫黑白树呢?不知道作者是不是特别喜欢看《红与黑》)。
6)心系祖国型:匈牙利命名法、木叶旋风。
7)比你强比你强型:C语言(比B语言强)、C++(比C语言强)、C#(比C++强2倍)、Eclipse(有哥在,Sun也要黯然失色);
8)跟你差不多型:Ruby(因为Perl与pearl谐音,你叫珍珠来我就叫宝石);
9)自信型:快速排序(只要有哥在,你们永远只能排第二)。
命名方法真是五花八门、不胜枚举,不过自信型的还真是挺少见的。这也难怪,就算是世界冠军也不敢说自己的记录永远没人破得了,更何况是一个见多识广的科学家呢?如果要用一个形容词来命名的话,叫“酷毙的、优雅的、梦幻般的”等等都没什么大不了的,但是如果叫快速排序——我们职业程序员兼副业起名专家都知道,一旦有了个更快的算法,就得叫QuickerSort,以及QuickestSort,以及ReallyQuickestSort,以及ReallyReallyQuickestSort……还有,所有的教科书都得加上一句话,“以前,快速排序确实是最快的排序算法,不过,自从XX算法发明以来,快速排序就名不符实了”,这可多没面子!
不过,事实证明Hoare的自信是很有根据的,自从这位仁兄在1962年发表了这个排序算法,它就一直稳居“最实用排序算法”的宝座。它到底厉害在什么地方?让我来一探究竟吧。快速排序
快速排序也是使用了分治法的思路,只是我怀疑Hoare以前在中国餐馆当过厨师,因为这哥们在分解前先给数组改了个刀。
分解:将数组s[p..r]划分成两个(可能为空)的子数组A和C以及一个元素x,划分后s={ A, x, C },并确保A中的每个元素都小于等于x,C中的每个元素都大于等于x。
解决:递归调用快速排序,对子数组A和C排序。
合并:只要将子数组处理成有序的,整个数组就是有序的,不需要合并。
01 static void QuickSort(int[] s, int p, int r)
02 {
03 // 判断是否能够直接解决
04 if(p < r) // 需要进一步分解
05 {
06 // 分解:将数组s[p..r]分解为 { A, x, C }的形式,A=s[p..q-1], x=s[q], C=s[q+1..r]。并且A中的所有元素都小于等于x,C中的所有元素都大于x
07 int q = Partition(s, p, r);
08
09 // 递归解决
10 QuickSort(s, p, q-1); // 排序A
11 QuickSort(s, q+1, r); // 排序C
12
13 // 合并:A和C处理成有序的之后,整个数组就是有序的,不需要合并
14 }
15 // p >= r时, s[p..r]是空数组或只有一个元素,本身就是有序的,直接返回
16 }
这个用来扒堆的Partition()函数看上去有些复杂。view sourceprint?01 static int Partition(int[] s, int p, int r)
02 {
03 int x = s[r];
04 int i = p-1;
05 for(int j = p; j<=r-1; j++)
06 {
07 if(s[j] <= x)
08 {
09 i++;
10 int temp = s[i];
11 s[i] = s[j];
12 s[j] = temp;
13 }
14 }
15 int temp2 = s[i+1];
16 s[i+1] = s[r];
17 s[r] = temp2;
18 return i+1;
19 }
第一个问题是,如何确定选哪个元素做x?因为s是无序的,所以我们无法确定s里面的元素的分布情况,所以答案是“只能随便选一个好了”,例如上面的代码就是选数组的最后一个元素s[r]作为x。
接下来,我们使用第一篇里面介绍的增量法生成A和C(A中的所有元素都小于等于x,C中的所有元素都大于x),A=s[p..i],C=s[i+1..j-1],U=s[j..r-1]为无序的子数组。每次迭代都会从U中拿出一个元素放入A或C中。我们把第一次调用Partition()的过程写一下。
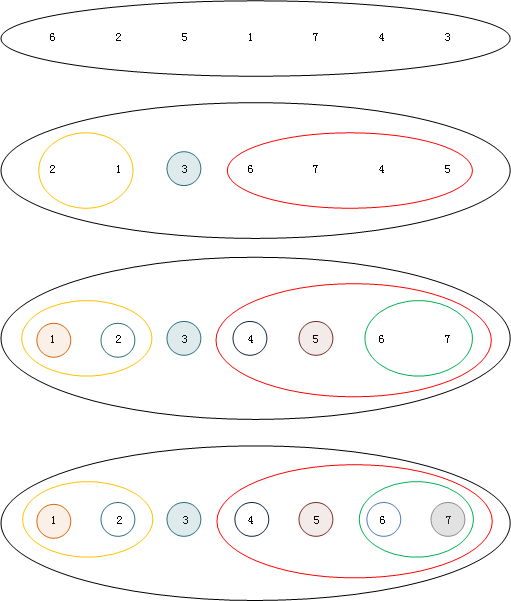
输入:s={ 6, 2, 5, 1, 7, 4, 3 };
初始时:A={ },C={ },U={ 6, 2, 5, 1, 7, 4 },x=3;
第1次迭代:A={ 6 },C={ },U={ 2, 5, 1, 7, 4 },将A中最后一个元素与U中第一个元素交换,得到A={ 2 },U={ 6, 5, 1, 7, 4 };
第2次迭代:A={ 2 },C={ 6 },U={ 5, 1, 7, 4 };
第3次迭代:A={ 2, 6 },C={ 5 },U={ 1, 7, 4 },将A中最后一个元素与U中第一个元素交换,得到A={ 2, 1 },C={ 5 }, U={ 6, 7, 4 };
第4次迭代:A={ 2, 1 },C={ 5, 6 }, U={ 7, 4 };
第5次迭代:A={ 2, 1 },C={ 5, 6, 7 }, U={ 4 };
迭代结束时:A={ 2, 1 },C={ 5, 6, 7, 4 }, U={ };
再将x与C的第一个元素交换位置,得到结果s={ A, x, C }, A={ 2, 1 },x=3,C={ 6, 7, 4, 5 }。快速排序的性能
快速排序和归并排序都是分治法,它们的区别在于,归并排序用(非常微小的)常量时间代价划分子数组,然后用Θ(n)的时间代价合并子数组;快速排序用Θ(n)的时间代价划分子数组,但是不需要合并操作。快速排序的平均运行时间为Θ(n log n),而且Θ(n log n)记号中隐含的常数因子很小。也就是说,快速排序通常要比归并排序快一点。为什么说快速排序的常数因子比较小呢?因为归并排序的Merge()函数是实打实的一个元素一个元素地进行赋值操作(而且得赋值2遍),而在快速排序的Partition()里面经常是一个j++就过去了。
不过还不能高兴得太早,刚刚说的只是平均时间代价。在某些极端情况下,例如输入是像 { 1, 2, 3 }或{ 3, 2, 1 }这种有序的数组,或者像{ 3, 3, 3 }这种所有元素的值都相同的时候,每次对数组的划分都会是{ A, x } 或 { x, C }这种极端不平衡的形式,在这种最坏情况下,快速排序的时间代价为Θ(n2),和插入排序一样慢。
所以,快速排序要想成为名副其实的“最实用排序算法”,必须得想办法爬过“有序输入”与“重复元素输入”这两座大山才行。对付“重复元素输入”
如果输入是 { 2, 2, 2, 2, 2 },我们希望能划分为 {{2,2}, 2, {2,2}} 这种形式,而不是 {{2,2,2,2}, 2}}。要想达到这个目标,只需要对Partition()稍作修改,让 i 和 j 分别从数组的两头向中间靠拢。
view sourceprint?01 static int EPartition(int[] s, int p, int r)
02 {
03 int x = s[r];
04 int i = p;
05 int j = r - 1;
06
07 // 每次迭代都确保 s[p..i-1] 中的每个元素都小于等于x,s[j+1..r] 中的每个元素都大于等于x
08 while (i <= j)
09 {
10 while (i<=r-1 && s[i] < x) i++;&nbs
补充:综合编程 , 其他综合 ,