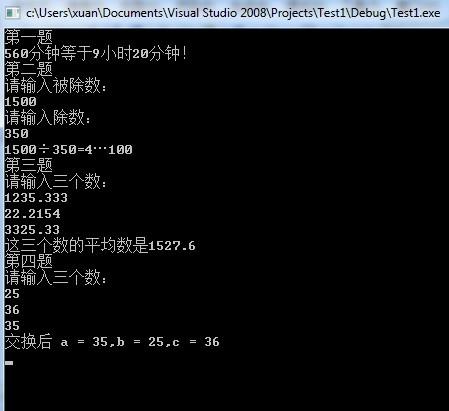
算法数据结构C++实现8 堆排序 难点分析
算法导论第六章开始就开始介绍堆排序。这是个非常难理解的排序算法,主要需要经过三个步骤:1 大顶堆化; 2 利用大顶堆化函数简历大顶堆; 3 最后再利用前面两个函数进行排序
这个算法有几个理解难点需要克服的:
1. 计算堆中的孩子节点要仔细,因为堆排序用的是一位数组表示二维二叉树的概念的,这都是人为地把数值中的元素和二叉树的一个节点一个节点地第一对应起来的,所以要程序员自己计算好这些对应关系。对二叉树概念不够熟悉的话,先要恶补一下。
2. 理解大堆顶化这个概念, 大堆顶化是使用递归法来进行,之所以这个算法可行的关键是:1) 这个算法只能应用于最大顶点mh的子树都已经是大顶堆了,否则的话就是不可大顶堆化的; 2)所以这个算法是从堆底起调用到对顶的。要理解一个元素(也可以说一个叶子)就肯定是大顶堆。
3. 因为是大顶堆,所以堆顶就肯定是所有元素中的最大值,所以每次都把最大值调到最后面,然后把最后面对应最大元素排除在堆外,再重新大顶堆化。比如说0到n个元素组成一个大顶堆,那么最后一个元素是n,那么第0个元素肯定是最大值,把第n个元素和第0个元素调换之后,那么最大值是第n个元素,而第0个元素就不是最大值了。这个时候,再吧0到n-1个元素组成一个大顶堆,那么就需要把这个堆重新大顶堆化,得到一个新的大顶堆,那么同理第0个元素依然是最大的。
下面是给出详细注释的程序, 而且标注了容易出错的地方和对应的理解难点:
#include<iostream>
#include<vector>
using namespace std;
int heapParent(int i)
{
return (i-1)/2;
}//查找堆排序中的节点父母,本例没有用到
int heapLeftChild(int i)
{
return i*2+1;
}//查找左孩子,注意其计算,一点也不能错。
int heapRightChild(int i)
{
return i*2+2;
}//查找右孩子,小心计算
template<typename T>
int triMax(vector<T>& heap, int currentIndex, int heapSize, int lChild, int rChild)
{
int largest = -1;
//小心两个&&判断的情况,因为编译器会先执行第一个判断,如果不成立,那么就不会执行第二个判断了
//所以下面还需要补一个判断条件
if(currentIndex<heapSize && lChild<heapSize && heap[lChild]>heap[currentIndex])
largest = lChild;
//这里最好有个safeguard判断i2是否超标,(补上面判断的不充分)
//否则容易当i2超标时,largest也超标,就会发生下标溢出
//这就会成为非常难debug的问题
else if(lChild<heapSize)
largest = currentIndex;
if(rChild<heapSize && heap[rChild]>heap[largest])
largest = rChild;
return largest;
}
template<typename T>
void maxHeapify(vector<T>& heap, int currentIndex, int heapSize)
{
int lChild = heapLeftChild(currentIndex);
int rChild = heapRightChild(currentIndex);
/*
int largest = currentIndex;
if(lChild<heapSize && heap[lChild]>heap[currentIndex])
largest = lChild;
//注意:这里变成用largest了,不是currentIndex,否则结果会不正确
//其中的思想就是:始终从父母节点,左右兄弟节点三个节点中选择出最大的
if(rChild<heapSize && heap[rChild]>heap[largest])
largest = rChild;
*/
//上面注释行独立成为一个函数会更加好理解
int largest = triMax(heap, currentIndex, heapSize, lChild, rChild);
//如果最大的不是父母节点,就说明这个堆不是大顶堆了,需要继续调整
//如果是的话就说明已经是大顶堆了,就不需要进一步递归了。
if(largest!=-1 && largest!=currentIndex)
{
swap(heap[currentIndex], heap[largest]);
maxHeapify(heap, largest, heapSize);
}
}//使用递归法来进行大顶堆化,之所以这个算法可行的关键是:
//这个算法只能应用于最大顶点currentIndex的子树都已经是大顶堆了,否则的话就是不可大顶堆化的
//所以这个算法是从堆底起调用到对顶的。可以说一个元素(也可以说一个叶子)就肯定是大顶堆
template<typename T>
void buildMaxHeap(vector<T>& heap, int heapSize)
{
for(int i = heapSize/2-1; i>=0; i--)
maxHeapify(heap, i, heapSize);
}
//这里必须从堆底起调用堆顶化maxHeapify,否则是无法建立大顶堆的。
template<typename T>
void heapSort(vector<T>& heap)
{
buildMaxHeap(heap, heap.size());
for(int i=heap.size()-1; i>0; i--)
{
swap(heap[i], heap[0]);
maxHeapify(heap, 0, i);
}
}
//因为是大顶堆,所以堆顶就肯定是所有元素中的最大值,所以每次都把最大值调到最后面,
//然后把最后面对应最大元素排除在堆外,再重新大顶堆化。
void test()
{
//初始化数组
double a[18] =
{32., 12., 0.7, 5., 0.1, 0.7, 0.8,0.7, 99., 0.4, 1., 2.5, 3.6, 5., 9., 12., 19.,23.};
vector<double> heap(a, a+18);
//排序前
for(int j=0; j<18; j++)
{
cout<<heap[j]<<" ";
}
cout<<endl;
//调用函数
heapSort(heap);
//排序后
for(auto x:heap)
cout<<x<<" ";
cout<<endl;
}
int main()
{
test();
return 0;
}
总结:
算法有点难理解,不过多过几遍就应该也可以的了,注意画图帮助理解,手动走一走程序。
编程书写一定要规范,变量命名一定要有意义,不能因为程序小而忽略这些方法,不然会养成坏习惯的,而且也不利于程序调试。不能贪图方便,快,而随便挑一个简短的命名变量。
这是我注释得最详细的程序之一了,希望都能看懂吧。
而且我这里有点创新之处的就是抽多一个triMax函数出来,我发现这样更方便理解,大家可以把这个程序和算法导论的对比一下有什么不一样。
注意其中的逻辑细节,否则很容易出错的。
补充:软件开发 , C++ ,