字符集之Unicode与字符串对象
1.unicode简介
如今,Windows操作系统的使用已经遍及世界,为使Windows操作系统及运行在操作系统上的应用软件更容易被世界所有国籍的用户所使用,需要使Windows及运行在其上的应用程序本地化,即使用用户本民族语言的字符集。字符集的不统一使得本地化变得很困难,这需要对操作系统的源代码根据不同的字符集进行全方位的定制,还要提供API的不同字符集的版本,此外,编写应用软件也要针对不同的字符集开发不同的版本。
在欧美地区,字符串被当作一系列以0结尾的单字节字符,这非常自然。使用strlen函数时,会返回一个以0结尾的单字节字符数组中的字符数。但是有些语言,如汉字,字符集的符号很多,而单字节字符集最多只能提供256个符号,这是远远不够的。因此,创立了双字节字符集DBCS(double byte character set)来支持这些语言。在双字节字符集中,字符串中的每个字符由1或2字节组成,因此也叫多字节字符集MBCS(multiple byte character set)。由于有些字符是1字节宽,而有些是2字节宽,这使得操作多字节字符串变得非常麻烦,使用strlen操作多字节字符串不能得到字符串的真正长度,而只能得到字符的字节数。
ANSI的C运行时库中没有支持多字节字符集的函数。VC++运行时库中包含有支持操作多字节字符串的函数,这些函数都以_mb开头,比如_mbstrlen。
Win32中提供了一些辅助函数来帮助操作多字节字符串。如表:
Win32中提供的操作多字节字符串的函数
函数
描述
LPTSTR CharNext(LPCTSTR lpszCurrentChar)
返回字符串中下一个字符的地址
LPTSTR CharPrev(LPCTSTR lpszStart,LPCTSTR lpszCurrentChar)
返回字符串中前一个字符的地址
BOOL IsDBcsLeadByte(BYTE bTestChar);
返回该字节是否是一个DBCS字符的第一个字节。
为了更方便地支持软件的国际化,一些国际著名的公司制定了一个宽字节的字符集标准—Unicode。该标准最早由Apple和Xerox公司在1988年创立,为发展和促进这一个标准,1991年创建了Unicode联盟,成员包括Adobe,Aldus,Apple,Borland,Digital,IBM,Lotus,Metaphore,Microsoft,
Novell,Sun,Taligent,Xerox等。
Unicode这个名称来自三个主要特征:通用(universal)—它解决了世界语言的需要;统一(uniform)—它为了保证效率而使用固定长度的代码;唯一(unique)—字符代码的重复将到了最低点。
Unicode字符串中所有字符都是16位的(2个字节),没有象MBCS字符那样的特殊字节来指示下个字节是同一字符的一部分还是一个新的字符,这意味着可以简单地增减一个指针来访问字符串中的所有字符。
由于Unicode用16位值来表示每个字符,因此可以表示65536个字符,这使得可对世界上所有的书面语言字符进行编码。目前,Unicode已经为Abrabic,Chinese bopomofo,Cyrillie(Russian),Greek,
Hebrew,Japanese kane,Korean hangul和English alphabets以及其他蚊子定义了码点(一个符号在字符集中的位置)。大量的标点符号、数学符号、技术符号、肩头、货币符号、发音符号以及其他符号也包括在这个字符集中。所有的这些符号总共约有34,000个码点,剩余的码点用于将来的扩展。这65536个字符分成若干个区间,如表所示。
Unicode字符集空间划分
16位代码
字符
0000-007F
ASCII
0080-00FF
拉丁字符
0100-017F
欧洲拉丁
0180-01FF
扩展拉丁
0250-02AF
标号准音标
02B0-02FF
修改字母
0300-036F
通用发音符号
0370-03FF
希腊字母
0400-04FF
西里尔字母
0530-058F
亚美尼亚字母
0590-05FF
希伯莱字母
0600-06FF
易做图字母
0900-097F
天城文字
3000-9FFF
中文、朝鲜文、日文
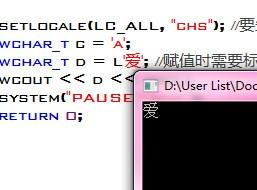
Unicode的字符串常量以字符串加前缀L表示,如:
wchar_t *pszInfo=L”It’s unicode string”;
2. Unicode与ANSI之间的字符串转换
多字节字符串转换成宽字节字符串的函数:
int MultiByteToWideChar(
UINT uCodePage, //源字符串的字符集编号(代码页)
DWORD DWFlags, //是否区分重音符号,一般不用,传0即可
PSTR pMultiByteStr,//双字节的源字符串
int cchMultiByte, //源字符串缓冲区大小,按字节计算
PWSTR pWideCharStr,//宽字符的目标字符串
int cchWideChar); //目标字符串的长度,按字符个数计算
宽字节转换成多字节的函数:
int WideCharToMultiByte(
UINT uCodePage , //代码页
DWORD dwFlags, //一般传0
PCWSTR pWideCharStr, //源宽字符串
int cchWideChar, //源字符串的长度,按字符计算
PSTR pMultiByteStr, //目标双字节缓冲区
int cchMultiByte, //目标缓冲区大小,按字节计算
PCSTR pDefaultChar, //转换失败的替代字符
PBOOL pfUsedDefaultChar //传出参数,表示是否有没转换成功的字符
)
示例:
char szGb[]="大小";
wchar_t *pszUni;
char *pszBig5;
int iLen;
const int CP_GBK=936; //GBK代码页
const int CP_BIG5=950; //繁体中文的代码页
//测试目标缓冲区的大小
iLen=MultiByteToWideChar(CP_ACP,0,szGb,-1,NULL,0);
pszUni=new wchar_t[iLen];//iLen把结束标记考虑进去了
//将GB2312字符串转换成UNICODE的
MultiByteToWideChar(CP_ACP,0,szGb,-1,pszUni,iLen);
//测试转换成多字节繁体字符串需要的缓冲区大小
iLen=WideCharToMultiByte(CP_BIG5,0,pszUni,-1,NULL,0,NULL,NULL);
pszBig5=new char[iLen];
//转换成繁体字符串
WideCharToMultiByte(CP_BIG5,0,pszUni,-1,pszBig5,iLen,NULL,NULL);
TRACE("%s\n",pszBig5);
delete []pszBig5;
delete []pszUni;
3. 建Unicode的VC++项目的一般步骤
1、 在项目设置的“菜单—Project—Settings—C/C++--Preprocessor definitions”中,将_MBCS预处理定义修改为_UNICODE;
2、 在“菜单—Tools—Debug”中,将“Display unicode strings”选项打勾;
3、 除非指定要使用char类型的字符串,否则应该将字符串常量用_T括起来,例如
//修改前 char szBuf[]="Hello!";
//修改后 TCHAR szBuf[]=_T("Hello!");
4、 有些数据类型要进行相应的转换,如
原数据类型
新数据类型
char
TCHAR
char *
LPTSTR
const char *
LPCTSTR
5、 原有字符串处理函数进行相应转换,一般规律为str***转换为_tcs***,例如
原函数
替换后的函数
strlen
_tcslen
strcpy
_tcscpy
strcat
_tcscat
sprintf
_stprintf 注意此处有不同
示例:
/* 转换前
char szBuf[]="Hello!";
char szBuf2[16];
char *pszBuf=szBuf;
const char *pszBuf2=szBuf;
strcpy(szBuf2,szBuf);
int iLen=strlen(szBuf2);
int iLen2=sizeof(szBuf)-1;
sprintf(szBuf2,"str is:%s",szBuf);
*/
//转换
补充:软件开发 , C语言 ,