基本的HTML文本解析器的设计和实现(C/C++源码)
作者:庄晓立 (liigo)
日期:2011-1-19
原创链接:http://blog.csdn.net/liigo/archive/2011/01/19/6153829.aspx
转载请保持本文完整性,并注明出处:http://blog.csdn.net/liigo
关键字:HTML,解析器(Parser),节点(Node),标签(Tag)
这是进入2011年以来,本人(liigo)“重复发明轮子”系列博文中的最新一篇。本文主要探讨如何设计和实现一个基本的HTML文本解析器。
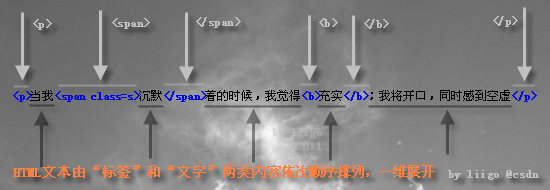
众所周知,HTML是结构化文档(Structured Document),由诸多标签(<p>等)嵌套形成的著名的文档对象模型(DOM, Document Object Model),是显而易见的树形多层次结构。如果带着这种思路看待HTML、编写HTML解析器,无疑将导致问题复杂化。不妨从另一视角俯视HTML文本,视其为一维线状结构:诸多单一节点的顺序排列。仔细审视任何一段HTML文本,以左右尖括号(<和>)为边界,会发现HTML文本被天然地分割为:一个标签(Tag),接一段普通文字,再一个标签,再一段普通文字…… 如下图所示:
标签有两种,开始标签(如<p>)和结束标签(</p>),它们和普通文字一起,顺序排列,共同构成了HTML文本的全部。
为了再次简化编程模型,我(liigo)继续将“开始标签”“结束标签”“普通文字”三者统一抽象归纳为“节点”(HtmlNode),相应的,“节点”有三种类型,要么是开始标签,要么是结束标签,要么是普通文字。现在,HTML在我们眼里更加单纯了,它就是“节点”的线性顺序组合,是一维的“节点”数组。如下图所示:HTML文本 = 节点1 + 节点2 + 节点3 + ……
在正式编码之前,先确定好“节点”的数据结构。作为“普通文字”节点,需要记录一个文本(text);作为“标签”节点,需要记录标签名称(tagName)、标签类型(tagType)、所有属性值(props);另外还要有个类型(type)以便区分该节点是普通文字、开始标签还是结束标签。这其中固然有些冗余信息,比如对标签来说不需要记录文本,对普通文字来说又不需要记录标签名称、属性值等,不过无伤大雅,简洁的编程模型是最大的易做图。用C/C++语言语法表示如下:
view plaincopy to clipboardprint?
enum HtmlNodeType
{
NODE_UNKNOWN = 0,
NODE_START_TAG,
NODE_CLOSE_TAG,
NODE_CONTENT,
};
enum HtmlTagType
{
TAG_UNKNOWN = 0,
TAG_A, TAG_DIV, TAG_FONT, TAG_IMG, TAG_P, TAG_SPAN, TAG_BR, TAG_B, TAG_I, TAG_HR,
};
struct HtmlNodeProp
{
WCHAR* szName;
WCHAR* szValue;
};
#define MAX_HTML_TAG_LENGTH (15)
struct HtmlNode
{
HtmlNodeType type;
HtmlTagType tagType;
WCHAR tagName[MAX_HTML_TAG_LENGTH+1];
WCHAR* text;
int propCount;
HtmlNodeProp* props;
};
enum HtmlNodeType
{
NODE_UNKNOWN = 0,
NODE_START_TAG,
NODE_CLOSE_TAG,
NODE_CONTENT,
};
enum HtmlTagType
{
TAG_UNKNOWN = 0,
TAG_A, TAG_DIV, TAG_FONT, TAG_IMG, TAG_P, TAG_SPAN, TAG_BR, TAG_B, TAG_I, TAG_HR,
};
struct HtmlNodeProp
{
WCHAR* szName;
WCHAR* szValue;
};
#define MAX_HTML_TAG_LENGTH (15)
struct HtmlNode
{
HtmlNodeType type;
HtmlTagType tagType;
WCHAR tagName[MAX_HTML_TAG_LENGTH+1];
WCHAR* text;
int propCount;
HtmlNodeProp* props;
};具体到编写程序代码,要比想象中容易的多。编码的核心要点是,以左右尖括号(<和>)为边界自然分割标签和普通文字。左右尖括号之间的当然是标签节点(开始标签或结束标签),左尖括号(<)之前(直到前一个右尖括号或开头)、右尖括号(>)之后(直到后一个左尖括号或结尾)的显然是普通文字节点。区分开始标签或结束标签的关键点是,看左尖括号(<)后面第一个非空白字符是否为/。对于开始标签,在标签名称后面,间隔至少一个空白字符,可能会有形式为“key1=value1 key2=value2 key3”的属性表,关于属性表,后文有专门的函数负责解析。此外有一点要注意,属性值一般有引号括住,引号内出现的左右尖括号应该不被视为边界分隔符。
下面就是负责把HTML文本解析为一个个节点(HtmlNode)的核心代码(不足百行,够精简吧):
view plaincopy to clipboardprint?
void HtmlParser::ParseHtml(const WCHAR* szHtml)
{
m_html = szHtml ? szHtml : L"";
freeHtmlNodes();
if(szHtml == NULL || *szHtml == L) return;
WCHAR* p = (WCHAR*) szHtml;
WCHAR* s = (WCHAR*) szHtml;
HtmlNode* pNode = NULL;
WCHAR c;
bool bInQuotes = false;
while( c = *p )
{
if(c == L")
{
bInQuotes = !bInQuotes;
p++; continue;
}
if(bInQuotes)
{
p++; continue;
}
if(c == L<)
{
if(p > s)
{
//Add Text Node
pNode = NewHtmlNode();
pNode->type = NODE_CONTENT;
pNode->text = duplicateStrUtill(s, L<, true);
}
s = p + 1;
}
else if(c == L>)
{
if(p > s)
{
//Add HtmlTag Node
pNode = NewHtmlNode();
while(isspace(*s)) s++;
pNode->type = (*s != L/

补充:软件开发 , C++ ,