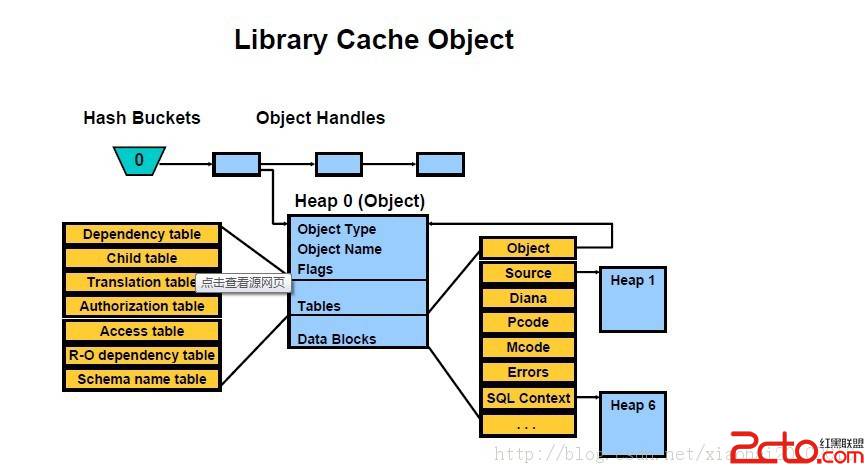
Oracle对Sql语句的软解析和硬解析
经常在论坛中,有人会在针对SQL优化方向提出:要避免SQL进行硬解析,从而提高SQL执行的效率。避免硬解析,确实是高效利用shared_pool的一种重要策略。通常情况下,作为开发人员,我们需要记住,为了最高效的利用共享池,我们编写的sql最好是可以共享的,比如绑定变量就是一个避免硬解析从而提高共享的有效手段。我们举一个相对极端的例子,在这里我们使用动态sql来模拟硬解析的场景:
ChenZw> drop table foo purge;
表已删除。
已用时间: 00: 00: 00.05
ChenZw> create table foo (x int);
表已创建。
已用时间: 00: 00: 00.07
ChenZw> create or replace procedure proc
2 as
3 begin
4 for i in 1..100000 loop
5 execute immediate
6 'insert into foo values ('||i||')';
7 end loop;
8 end;
9 /
过程已创建。
已用时间: 00: 00: 00.05
ChenZw> exec proc;
PL/SQL 过程已成功完成。
已用时间: 00: 00: 47.75
ChenZw>
可以看到上面的执行时间是47.75秒,我们可以去查看能够体现Shared_pool里面共享sql区域中的一个数据字典中的内容:

我们发现在其中,最早的那个解析是插入96581的那条数据,最末的解析是插入100000的那条解析,一共是6281条数据。
现在我们换一种方式重新来执行上面的语句,我们使用动态sql的绑定变量的方式来写这个sql语句,我们尝试的代码和结果如下:
ChenZw> drop table foo purge; 表已删除。 已用时间: 00: 00: 00.13 ChenZw> create table foo (x int); 表已创建。 已用时间: 00: 00: 00.03 ChenZw> drop procedure proc; 过程已删除。 已用时间: 00: 00: 00.04 ChenZw> create or replace procedure proc 2 as 3 begin 4 for i in 1..100000 loop 5 execute immediate 6 'insert into foo values (:x)' using i; 7 end loop; 8 end; 9 / 过程已创建。 已用时间: 00: 00: 00.06 ChenZw> alter system flush shared_pool; 系统已更改。 已用时间: 00: 00: 00.92 ChenZw> exec proc; PL/SQL 过程已成功完成。 已用时间: 00: 00: 04.50 ChenZw>
我们查看保存在v$sql中的内容,可以看到如下的内容:

可以很清楚的看到,插入语句被解析了一次,而调用了十万次,因此,执行效率从第一次的48秒钟,变为现在的5秒钟。
那两个到底有什么区别呢?这个例子跟sql语句的软解析和硬解析又有什么关系呢?
下面是Oracle Concepts Guide中给出的图:
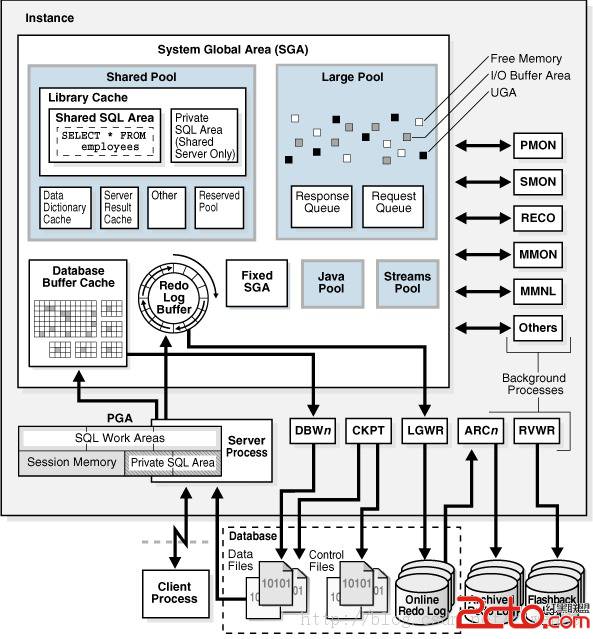
先给出一个结论好了,上面第一种情况,就是sql硬解析次数太多而导致了执行效率低下,第二种情况,因为降低了sql的硬解析,从而提高了sql的运行效率。
第一种情况,当第一条insert into foo values (1)执行的时候,因为没有采用绑定变量的方式,因此在上述结构图的SGA中,首先对该条语句进行判断语法校验,确认权限等等各种准备工作之后,通过hash得形成一个解析后的信息,放置到SGA中。然后当insert into foo values (2)来执行的时候呢,做了同样的工作。
第二种情况,当第一条insert into foo values (:x)执行的时候,也是对该条语句进行语法判断等等准备工作之后,将解析之后的信息,放到了SGA当中,但是当第二条语句来到的时候,Oracle就不需要再做结息的工作了,直接将上一次执行之后的结果拿出来运行就好了。
所以,我们可以看到软解析和硬解析的区别了。
如果Oracle在sql进行解析的时候,能够从SGA中找到之前曾经解析过的信息直接执行的情况,被称作SQL的软解析。如果Oracle在sql进行解析的时候,找不到可以拿来就用的sql,必须重新解析信息的情况,就是SQL的硬解析,sql的软解析与硬解析在效率上大概有接近50-60倍性能的差距(源自某个论坛上一个Oracle
高手的试验结果,具体地址忘记了)。
--作者 陈字文(热衷于PM\ORACLE\JAVA等,欢迎同行交流):ziwen#163.com 扣扣:4零9零2零1零零
另外,通过上面的例子可以看到,存储解析结果的内存空间并不是非常大的,例如我们第一个例子,解析了10万次,但是仅仅存放了6281条解析后的数据。通过对相关语句的分析,我们也可以知道,该块内存的算法应该是最近最少使用算法。