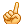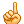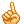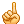关于数据统计的问题,期待高手给出代码
1 11 2
1 3
1 4
1 6
1 7
2 1
2 2
2 5
2 6
2 7
如何做,才能得出如下的结果
1,1-4、6-7
2,1-2、5-7
看不懂。。。 是在EXCEL里的两列
我想让他们按第一列都是1的,统计成:1,1-4、6-7,第一列为2的,统计成:2,1-2、5-7,不知道能不能看明白 -表示连续递增?步长是1? SQL SERVER不清楚怎么写,
在ORACLE里可以实现,只能罗列出来,不能进行排序,或者将连续编码进行组合
--查询语句
select a, wm_concat(b)
from (select 1 as a, 1 as b
from dual
union
select 1, 2
from dual
union
select 1, 3
from dual
union
select 1, 4
from dual
union
select 1, 6
from dual
union
select 1, 7
from dual
union
select 2, 1
from dual
union
select 2, 2
from dual
union
select 2, 5
from dual
union
select 2, 6
from dual
union
select 2, 7 from dual)
group by a
--结果
1 1 1,7,6,4,3,2
2 2 1,7,6,5,2 这个东西只要先按这两列排一下序,然后遍历一下就OK了 排序试过了,没用
-表示连续递增,步长是1,也就是1、2、3、4 、统计称1-4,6、7、8、9,统计成6-9
先把EXCEL中的内容,保存到数据库临时表中,然后排序遍历,判断是否连续递增,从而得到结果。 先睡一觉 稍后给你答案
CREATE TABLE #t(ID INT,VALUE INT)
INSERT INTO #t
SELECT 1 AS ID,1 AS VALUE UNION ALL
SELECT 1, 2 UNION ALL
SELECT 1, 3 UNION ALL
SELECT 1, 4 UNION ALL
SELECT 1, 6 UNION ALL
SELECT 1, 7 UNION ALL
SELECT 2, 1 UNION ALL
SELECT 2, 2 UNION ALL
SELECT 2, 5 UNION ALL
SELECT 2 ,6 UNION ALL
SELECT 2, 7
select a.id,a.value
from #t a,#t b
where a.value+1=b.value
and a.id=b.id
--求断点
;with cte as(
SELECT a.id,row_number() OVER (partition by id order by value) as id1,a.VALUE
FROM #t a
WHERE NOT EXISTS(SELECT 1 FROM #t b WHERE a.id=b.id AND a.[VALUE]+1=b.value)
)
--得到断点下的所有值
,cteb as(select a.id,a.value,b.id1,b.value as value1 from #t a,cte b
where a.id=b.id
and a.value<=b.value
--order by a.id, b.id1,a.value
)
--过滤断点下值的重复项
,ctec as(
select * from cteb a where not exists
(select 1 from cteb b where a.id=b.id and a.id1>b.id1 and a.value=b.value)
)
,cted as(
select id,id1,min(value) as [min],max(value) as [max]
from ctec
group by id,id1)
select * into #t1 from cted
declare @sql varchar(max),@result varchar(max)
select @sql='Select ID,'
select @sql=@sql+' max(case when ID=' +convert(varchar(5),id)+' And ID1='+ convert(varchar(5),id1)+
' then convert(varchar(5),[min])+'+'''-'''+'+convert(varchar(5),[max]) else '''' end) AS COL' +convert(varchar(5),id)+'_'+convert(varchar(5),id1) +','+char(10)
from #t1
select @sql=left(@sql,len(@sql)-2)+' From #t1 group by id'
print @sql
exec(@sql)
Drop #t
Drop #t1
ID COL1_1 COL1_2 COL2_1 COL2_2
1 1-4 6-7
2 1-2 5-7
补充:VB , 基础类