Python抓取花瓣网图片脚本
/**author: insun
title:Python抓取花瓣网图片脚本
blog:http://yxmhero1989.blog.163.com/blog/static/112157956201311994027168/
**/
花瓣网的架构:LVS + nginx reverse proxy + NodeJS cluster,使用MySQL、Redis作为主要的数据存储方案。
是国内类pinterest中图片质量比较高的网站,因为他家早前开的又拍云,没理由做不好图片存储。
昨天写了个粗糙的花瓣的抓取程序 网络上的人都抱怨这个有难度 其实是你们没静心下来分析
譬如说美女这一栏:http://huaban.com/favorite/beauty/
页面是下拉刷新加载页面
加载中的内容应该是ajax请求的,对付ajax请求没有什么好的办法,只有抓取页面的JS,分析JS进行抓取
http://huaban.com/favorite/beauty/?hdbccuho&max=46163269&limit=20&wfl=1
http://huaban.com/favorite/beauty/?hdbccuhx&since=46181596&limit=100&wfl=1
http://huaban.com/favorite/beauty/?hdbccui0&since=46181596&limit=100&wfl=1
http://huaban.com/favorite/beauty/?hdbchu1m&since=46181596&limit=100&wfl=1
http://huaban.com/favorite/beauty/?hdbccui8&since=46181596&limit=100&wfl=1
http://huaban.com/favorite/beauty/?hdbcz9bo&since=46185848&limit=100&wfl=1
http://huaban.com/favorite/beauty/?hdbcz9bq&since=46185848&limit=100&wfl=1
http://huaban.com/favorite/beauty/?max=46178625&limit=20&wfl=1
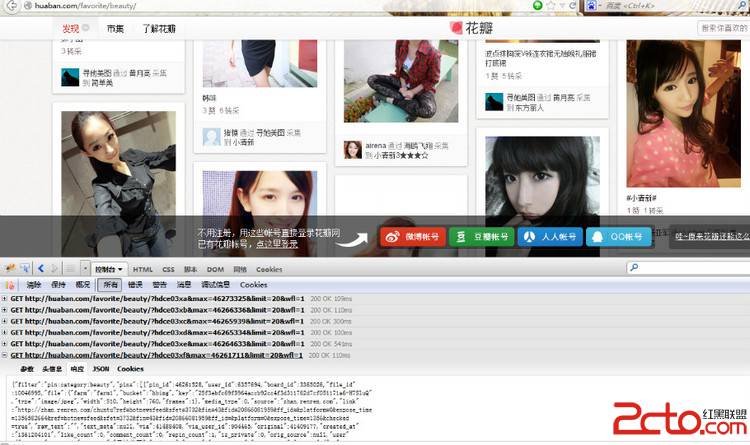
正确的请求就返回一串Json
{"filter":"pin:category:beauty",
"pins":[{"pin_id":46189172,"user_id":755324,"board_id":2425342,"file_id":11427806,"file":{"farm":"farm1","bucket":"hbimg","key":"3d971b295b79e397765a0dde013cf574b22166848924-mlLarI","type":"image/jpeg","width":354,"height":440,"frames":1},"media_type":0,"source":null,"link":null,"raw_text":"春季造型攻略 #小清新#","text_meta":{"tags":[{"start":7,"offset":5}]},"via":1,"via_user_id":0,"original":null,"created_at":"1361176634","like_count":0,"comment_count":0,"repin_count":0,"is_private":0,"orig_source":null,
"user":{"user_id":755324,"username":"爱造型","urlname":"aizaoxing","created_at":"1346810536",
"avatar":{"id":5664391,"farm":"farm1","bucket":"hbimg","key":"97f2e2cbdee392f3f7642ec8bd12447f673f73221007-yThjgP","type":"image/jpeg","width":100,"height":100,"frames":1}},"board":{"board_id":2425342,"user_id":755324,"title":"爱造型美丽分享#美丽造型#","description":"","category_id":"beauty","seq":4,"pin_count":41,"follow_count":19,"like_count":0,"created_at":"1348629162","updated_at":1361176634,"is_private":0}}]
,"promotions":null}
{"filter":"pin:category:beauty","pins":[],"promotions":null}
分析与实践中发现 对于这个一样的链接:http://huaban.com/favorite/beauty/?hdbcz9bq&max=46185848&limit=100&wfl=1
可以简化为http://huaban.com/favorite/beauty/?max=46185848&limit=100&wfl=1
第一个参数是没用的变换值,从0-9,a-b变换。max是pin图片的id,你可以火狐查看,limit是请求max后面的多少张,目前限制最多100张。这样我们就清楚了。
根据上面的链接读出json串,提取里面的key值(注意有2个key,后面的那个key是头像,我们不需要的),那就正则一下处理OK。
然后加上http://img.hb.aicdn.com/拼凑成img_url链接。
设置id起点和终点 beauty的抓取模块是这样的:
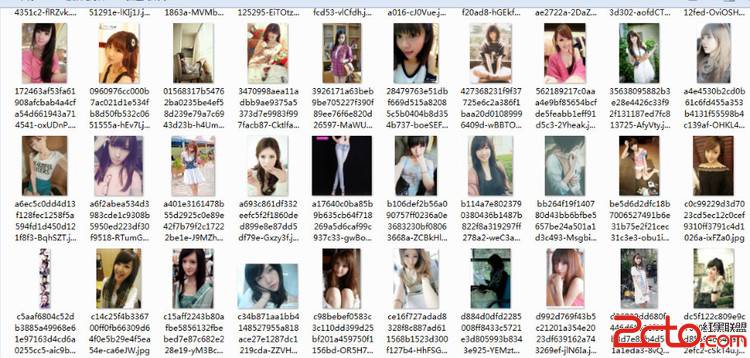
后来发现图片的类型可能有:jpeg,pjpeg,gif,bmp 做了下修改 保存成他原本的类型。
#!/usr/bin/env python
# -*- encoding:utf-8 -*-
# author :insun
#http://huaban.com/favorite/beauty/
import urllib,urllib2,re,sys,os
reload(sys)
sys.setdefaultencoding('utf-8')
#直接访问http://huaban.com/favorite/beauty/会返回最新的20张
#url = 'http://huaban.com/favorite/'
if(os.path.exists('beauty') == False):
os.mkdir('beauty')
def get_huaban_beauty():
start = 46284804
stop = 46285004
limit = 100 #他默认允许的limit为100
for i in range(start,stop):
url = 'http://huaban.com/favorite/beauty/?max='+str(stop)+'&limit='+str(limit)+'&wfl=1'
try:
i_headers = {"User-Agent": "Mozilla/5.0(Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1)\
Gecko/20090624 Firefox/3.5",\
"Referer": 'http://huaban.com/'}
req = urllib2.Request(url, headers=i_headers)
html = urllib2.urlopen(req).read()
reg = re.compile('"file":{"farm":"farm1", \
"bucket":"hbimg",.+?"key":"(.*?)",.+?"type":"image/(.*?)"',re.S)
groups = re.findall(reg,html)
for att in groups:
att_url = att[0]
img_type = att[1]
img_url = 'http://img.hb.aicdn.com/' + att_url
urllib.urlretrieve(img_url,'beauty/'+att_url+'.'+img_type)
print img_url +'.'+img_type + ' download success!'
except:
print 'error occurs'
sys.exit(-1)
get_huaban_beauty()
补充:Web开发 , Python ,上一个:Python日期(月份)相减思路
下一个:python爬虫抓取心得分享




- 更多python疑问解答:
- python 把图片转换成base64代码 python 把base64代码转换成图片
- 利用python进行网络图片下载 python批量下载远程图片
- 记录Python读写文件的代码和方法
- Python如何把图片转为Base64字符串
- python用requests.get批量下载网络远程图片的代码
- 疑难杂症,关于python与C#输出重定向
- 最近写的一个软件,对照下c#,c++,DELPHI,VB,易语言,PYTHON,PHP等执行效率
- 利用C#4.0调用IronPython脚本
- bat 执行定时python 打开url 谁搞过,帮忙看一下语句有什么问题
- 求助!在线等!python调用C#的.dll库
- Python 快速界面开发?求IDE和资料..中文的最好
- python如何读取XML文件中的
- .NET运行IronPython脚本错误
- 新手之前对编程无概念现在想转这行,想尽快入门,java ,python,.net、php、C之间如
- 新手之前对编程无概念现在想转这行,想尽快入门,java ,python,.net、php、C之间如