python爬虫抓取心得分享
/**
author: insun
title:python 爬虫抓取心得分享
blog:http://yxmhero1989.blog.163.com/blog/static/112157956201311821444664/
**/
0x1.urllib.quote('要编码的字符串')
如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用:
urllib.quote('要编码的字符串')
query = urllib.quote(singername)
url = 'http://music.baidu.com/search?key='+query
response = urllib.urlopen(url)
text = response.read()
0x2. get or post urlencode
如果在GET需要一些参数的话,那我们需要对传入的参数进行编码。
import urllib
def url_get():
import urllib
params = urllib.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
f = urllib.urlopen("http://www.musi-cal.com/cgi-bin/query?%s" % params)
print f.read()
def url_post():
import urllib
params = urllib.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
f = urllib.urlopen("http://www.musi-cal.com/cgi-bin/query", params)
print f.read()
0x3.urllib urllib2 proxy 代理
如果你请求对方的网页,确不想被封IP的话,这个时候就要用到代理了,其实用urllib代理还是比较简单的:
import urllib
def url_proxy():
proxies = {'http':'http://211.167.112.14:80'}#或者proxies = {'':'211.167.112.14:80'}
opener = urllib.FancyURLopener(proxies)
f = opener.open("http://www.dianping.com/shanghai")
print f.read()
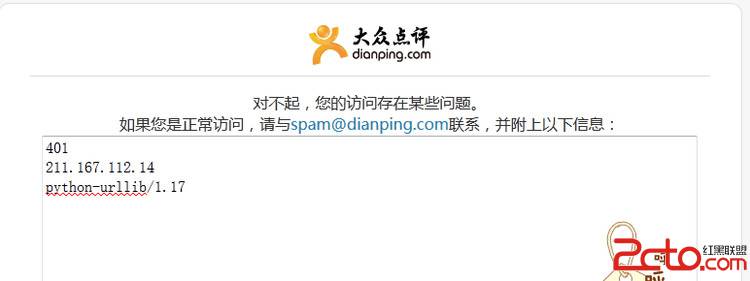
只用一个代理IP的话 有时候弄巧成拙了 恰好被大众点评给检测出来了
401
211.167.112.14
python-urllib/1.17
那么就试试多个IP代理
import urllib
def url_proxies():
proxylist = (
'211.167.112.14:80',
'210.32.34.115:8080',
'115.47.8.39:80',
'211.151.181.41:80',
'219.239.26.23:80',
)
for proxy in proxylist:
proxies = {'': proxy}
opener = urllib.FancyURLopener(proxies)
f = opener.open("http://www.dianping.com/shanghai")
print f.read()
这回没问题了。
有的时候要模拟浏览器 ,不然做过反爬虫的网站会知道你是robot
例如针对浏览器的限制我们可以设置User-Agent头部,针对防盗链限制,我们可以设置Referer头部
有的网站用了Cookie来限制,主要是涉及到登录和限流,这时候没有什么通用的方法,只能看能否做自动登录或者分析Cookie的问题了。
仅仅是模拟浏览器访问依然是不行的,如果爬取频率过高依然会令人怀疑,那么就需要用到上面的代理设置了
import urllib2
def url_user_agent(url):
'''
proxy = 'http://211.167.112.14:80'
opener = urllib2.build_opener(urllib2.ProxyHandler({'http':proxy}), urllib2.HTTPHandler(debuglevel=1))
urllib2.install_opener(opener)
'''
i_headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1) Gecko/20090624 Firefox/3.5",\
"Referer": 'http://www.dianping.com/'}
req = urllib2.Request(url, headers=i_headers)
return urllib2.urlopen(req).read()
#print url_user_agent('http://www.dianping.com/shanghai')
就算设置了代理,代理的ip也有可能被封,还有另外一种终极的办法来防止被封,那便是使用time库的sleep()函数。
import time
for i in range(1,10):
....#抓取逻辑
time.sleep(5)
抓的地址是http://www.dianping.com/shanghai
直接抓http://www.dianping.com的话会location到城市列表去 反而达不到效果
header: Location: /citylist
提供一段代理IP
proxylist = (
'211.167.112.14:80',
'210.32.34.115:8080',
'115.47.8.39:80',
'211.151.181.41:80',
'219.239.26.23:80',
'219.157.200.18:3128',
'219.159.105.180:8080',
'1.63.18.22:8080',
'221.179.173.170:8080',
'125.39.66.153:80',
'125.39.66.151:80',
'61.152.108.187:80',
'222.217.99.153:9000',
'125.39.66.146:80',
'120.132.132.119:8080',
'119.7.221.137:82',
'117.41.182.188:8080',
'202.116.160.89:80',
'221.7.145.42:8080',
'211.142.236.131:80',
'119.7.221.136:80',
'211.151.181.41:80',
'125.39.66.131:80',
'120.132.132.119:8080',
'112.5.254.30:80',
'106.3.98.82:80',
'119.4.250.105:80',
'123.235.12.118:8080',
'124.240.187.7
补充:Web开发 , Python ,