汇编语言基本概念(续5)
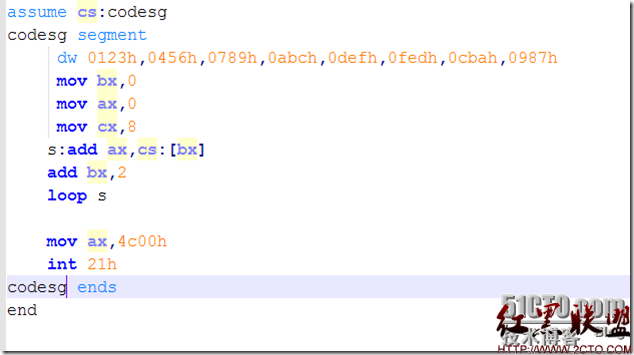
前面我们写的程序都比较简单,通常在一个代码段就搞定了,所需要的空间也比较小。那么如果代码量大了怎么办呢?如何分配空间及如何规定不同的寄存器段也是非常重要的问题。通常程序需要内存空间有两种途径,一种是自己分配,在加载过程中指定内存空间,另一种是执行过程中向操作系统分配。第一种情况下对内存的管理,通常需要在程序中进行说明,在汇编语言中,对通常程序意义上的数据、代码、栈等按段分配内存,但这里按段并不表示唯一。也就是说代码段中也可以存储数据。比喻说我们用dw(define word)来定义字型数据,并将它放在代码段上。这些数据就是从代码段的首地址开始按个存放。如下所示:
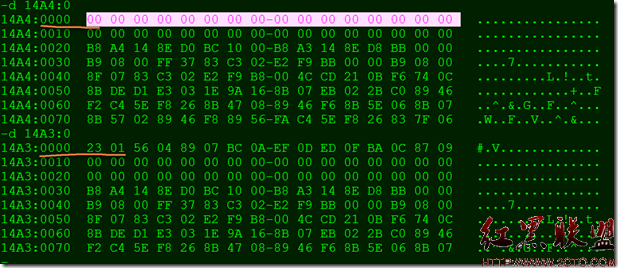
以dw定义的8个16位数据,分别占据代码段起始的前16个内存,以段前缀表示则为cs:0,cs:2…..cs:E
从上面可以看出代码段的前16个字节是数据,那么因为机器执行是按照CS:IP指令进行设置的,而在这种情况下,它的IP是0,那么显然不可以,我们必须改变IP的值,从源码的角度,是我们设置start标志位。
在程序的第一条指令加上标号start,并且用end结束这个star,这样操作系统DEBUG或者COMMAND将可执行程序装入内存并进行执行,这里有一点要说明的,是DEBUG如何知道设置IP为start点的指令呢?这个是由可执行文件的描述信息来确定,可执行文伯通常由描述信息和程序指令组成,汇编程序中伪指令通常生成的就是描述信息,这些描述信息在执行过程中就会对应成相应的执行地址,如start就是入口地址。
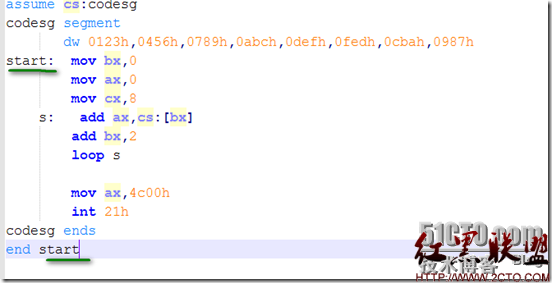
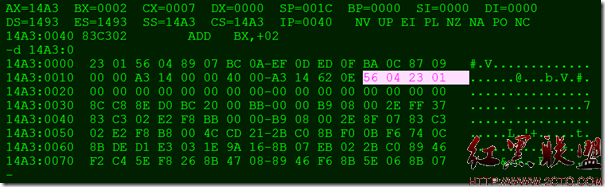
同前面一样,在一段代码段空间,也可以分配出一段空间来作为栈空间,只要指定SS:SP的地址段就可以开设出一段栈空间来,如下所示:
在上图中,前0-15个字节中默认存入一些数据,后16-31设为栈空间,并通过通用寄存器将SS,SP设为第32个内存空间。如下所示:
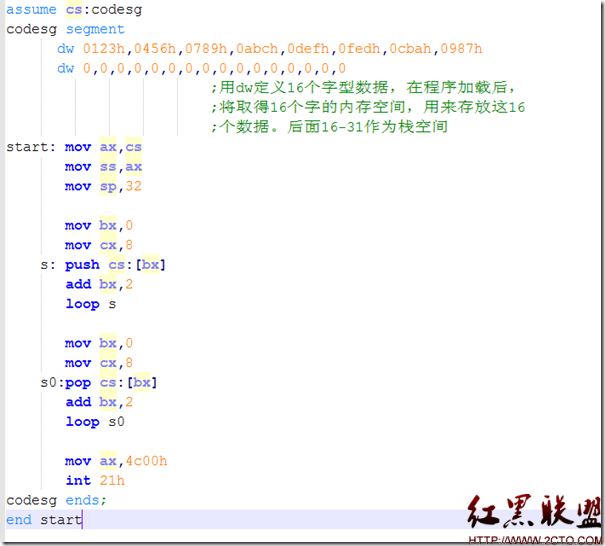
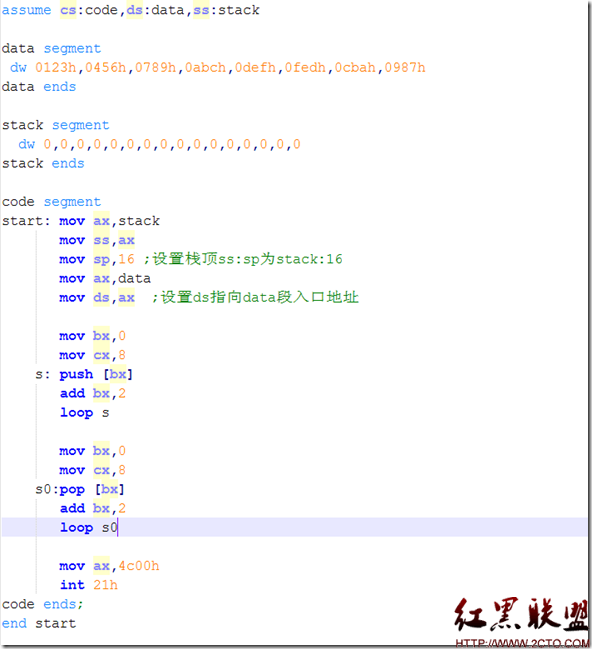
前面我们都是将不同类型的内存空间都分配在代码段,对8086来说,一个段中最多只有64KB,很容易写满的,另外都搞在一起也是非常混乱的。那么有什么好方法呢?汇编设计了不同的段来定义不同类型的内存空间。如下所示,可将数据、栈、和代码放到不同的段中。
从上面可以看出,我们可以使用assume定义多个段,并将每种段的与段寄存器类型关联起来。每个段的首地址可以直接使用段标记符号来表示。如上图中的data就表示一段地址的第一个地址14A4:0
注意通过assume只是类型定义,非直接指定,除了CS中未指定START之外,默认是第一个,其它像data地址不能直接等同于ds内容。我们必须用指令mov ax,stack mov ss,ax mov sp 20h这样的方式去设置。
汇编同所有程序一样,编译器都是按文件顺序进行代码处理的,因此分配段时也是按顺序分配大小,通常分配配都是以16个单元一次分配,小于16个数据,以16个分配。因此,
前面对内存空间进行分段存放,显示汇编的一定灵活性,实际上汇编功能还是非常强大的。在介绍汇编直接处理字符数据之前,首先看一下两个新指令and与or,也不用多说,其实是对二进制进行按位与与或。
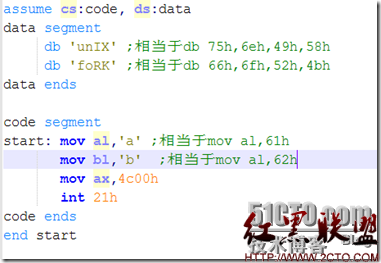
原理比较简单,但有两个常见的用法就是通过特殊的或对象和与对象可将原始数据的对应位取出或全置0。讲到汇编里处理字符,就不得不说到ASCII码,理解ASCII一样非常简单,就是一串编辑,为显示使用,这些编辑CPU可以直接来加减计算,但对显示器来说则是绘制图形的标记。因此,从CPU来说,ASCII码只是数据,但从显示来说,就是不同的图形。从汇编的角度来说,汇编是程序开发,应用于CPU计算,因此理论上这些ASCII码只是代表一定的数据。在程序编写过程中为了显示和程序的可理解性,才使用字符的。如下所示:
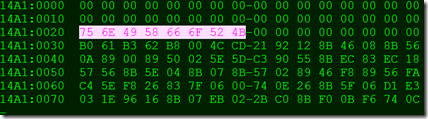
其对应的数据段内存值如下所示:
前面我们已经说过了[bx]可以代表一个内存地址ds:[bx],实际上[bx+idata]也可以表示一个内存地址。如mov ax,[bx+200]表示将一个内存单元的内容送入ax,这个内存单元的长度为2个字节,地址为段地址为ds,偏移地址为bx中的数值加上200。 (ax)=((ds)*16+(bx)+200)。还可以写成如下:




补充:软件开发 , 其他 ,