算法学习笔记----归并排序
一、算法描述
归并排序算法完全遵循分治模式,将问题分解为若干子问题,如果子问题的规模足够小,则直接求解,否则递归地求解各子问题。算法步骤如下所示:
1)将待排序的n个元素的序列分解为各具n/2个序列的两个字序列
2)使用归并排序递归地将两个子序列排序
3)将两个已排序的子序列合并,生成排好序的序列。
二、算法实现
1、递归版本
为了避免在合并两个子序列时每次都要检查是否某个子序列已全部处理完,在每个子序列最后都添加了一个“哨兵”元素。源码如下所示:
[cpp]
#include <stdio.h>
#include <errno.h>
#ifndef INT_MAX
#define INT_MAX ((int)(~0U>>1))
#endif
#define ARRAY_SIZE(__s) (sizeof(__s) / sizeof(__s[0]))
static void merge(int *a, int start, int mid, int end)
{
int nl = mid - start + 1;
int nr = end - mid;
int sentinel = INT_MAX;
int left[nl + 1], right[nr + 1];
int i, j, k = start;
for (i = 0; i < nl; ++i) {
left[i] = a[k++];
}
/* Set sentinel */
left[i] = sentinel;
for (j = 0; j < nr; ++j) {
right[j] = a[k++];
}
/* Set sentinel */
right[j] = sentinel;
i = j = 0;
for (k = start; k <= end; ++k) {
if (left[i] <= right[j]) {
a[k] = left[i++];
} else {
a[k] = right[j++];
}
}
}
static void merge_sort(int *a, int start, int end)
{
int mid;
if ((start >= 0) && (start < end)) {
mid = (start + end) /2 ;
merge_sort(a, start, mid);
merge_sort(a, mid + 1, end);
merge(a, start, mid, end);
}
}
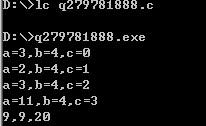
int main(void)
{
int source[] = { 7, 5, 2, 4, 6, 1, 5, 3};
int i;
printf("Before sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
merge_sort(source, 0, ARRAY_SIZE(source) - 1);
printf("After sort: ");
for (i = 0; i < ARRAY_SIZE(source); ++i) {
printf("%d ", source[i]);
}
printf("\n");
return 0;
}
2、迭代版本
这个版本是在易做图上看到的, 做一个简单的分析,记录一下,代码如下所示:
[cpp]
#include <stdio.h>
#include <errno.h>
#define ARRAY_SIZE(__s) (sizeof(__s) / sizeof(__s[0]))
void merge_sort_iterate(int *source, int n)
{
int i, left_min, right_min, left_max, right_max, next;
int tmp[n];
for (i = 1; i < n; i *= 2) {
/*
* 将数组分段处理,每个段的长度为2*i。其中每段的前一半作为左半部,
* 后一半作为右半部,然后合并。
*/
for (left_min = 0; left_min < n - 1; left_min = right_max) {
/*
* left_max其实是左半部的长度,right_max其实是右半部的长度,
* 所以应该叫left_len、righ_len更合适一些。
*/
right_min = left_max = left_min + i;
right_max = left_max + i;
if (right_max > n) {
right_max = n;
}
next = 0;
/*
* 合并当前段中左半部和右半部的元素
*/
while ((left_min < left_max) &&
(right_min < right_max)) {
tmp[next++] = source[left_min] > source[right_min] ?
source[right_min++] : source[left_min++];
}
/*
* 左半部和右半部从长度为1开始处理,每次处理后,左半部和右半部
* 组成的段是排好序的,所以在下次处理中,每个段的左半部和右半部
* 已经是排好序的。如果判断条件为真,说明右半部中当前元素已经全
* 部放在tmp中,而左半部中剩余的元素肯定比已经放在tmp中的元素大,
* 因此循环将左半部中剩余的元素放在段的后面。