大数据过滤及判断算法 -- Bitmap / Bloomfilter
今天,有个同学向我咨询大数据的一些面试题,其中一类比较有代表性比如判断是否在集合内,比如10个url,判断一个url是否在集合内,还比如有个1~100万个连续无序数字,随机取出里面的N个,求这N个数字等等。这类问题都需要一个大的数据集合,而且每个数据单元都很小,比如一个int 。很大程度上,这类问题可以用Bitmap或者Bloomfilter来做,基本思想就是开辟一块大内存,然后利用一个byte里的8个bit来实现按位标记元素。因为地址空间都是连续的,所以查找都是O(1)的。这里需要说的是,BloomFilter判断属不属于集合,在理论上是存在误判的,如果要求数据100%正确,则不要使用BloomFilter。
进入正题,Bitmap正如其名,就是一块内存,内存是一个一个连续的位图,每一个位通过0、1代表一个元素的有无。比如数字为N的数字对应到Bitmap就是第N/8个byte的字节,和第N%8个01位,这么映射。所以通过检测对应的bit位即可知道数据在不在集合内,而且能保证正确。直接上代码 :
[cpp]
#include <cstdlib>
#include <iostream>
#include <algorithm>
#include <vector>
#include <stddef.h>
#include <memory.h>
#define BYTES 12500
int main()
{
srand((unsigned int)time(NULL));
size_t total_numbers = 100000;
typedef std::vector<int> SetContainer;
typedef std::vector<int>::iterator SetIterator;
SetContainer numbers;
numbers.reserve(total_numbers);
int r1 = rand() % total_numbers;
int r2 = r1 + 1000;
// generate total_numbers-2 numbers
for(int i=0;i!=total_numbers;++i) {
if (i!=r1 && i!= r2)
numbers.push_back(i);
}
std::cout<<"["<<numbers.size()<<"] insert ok";
std::cin.get();
// shuffle
std::random_shuffle(numbers.begin(),numbers.end());
unsigned char *bitmap = (unsigned char*)malloc(BYTES);
memset(bitmap,0,BYTES);
for (SetIterator itr=numbers.begin();itr!=numbers.end();++itr) {
ptrdiff_t forward = (*itr) / 8;
size_t offset = (*itr) % 8;
bitmap[forward] |= (0x80UL >> offset);
}
std::cout<<"Bitmap build ok";
std::cin.get();
for (int j=0;j!=BYTES;++j) {
if (bitmap[j]!=0xFF) {
std::cout<<"FIND ";
unsigned long num = j * 8;
unsigned char check = bitmap[j];
unsigned char bit = 0;
while(bit!=8) {
if (0 == (check&(0x80UL>>bit)))
std::cout<<"["<<(num+bit)<<"] ";
bit++;
}
std::cout<<std::endl;
}
}
std::cout<<"DONE";
std::cin.get();
free(bitmap);
return 0;
}
BloomFilter,是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,适合与比Bitmap更多量的数据,通过图片看一下方法流程 :
1、初始化一块大内存用于存放01标志位:
2、通过使用N个hash函数(N==3),对同一个值Hash多次哈希,然后同Bitmap一样映射到Bloomfilter中去,
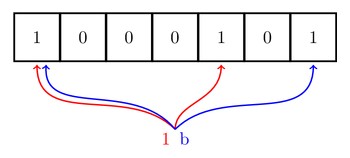
3、检测时,同样通过N次哈希,在映射的位中去找,并要保持映射的每一位都是1的情况下,即检测处包含关系。正如前面说的,BloomFilter可能有误判,误判的几率取决于Hash函数的个数,Hash函数冲撞的概率,以及Bloomfilter开开辟的内存大小。Hash函数的个数要取个合适的值,大了会造成效率问题,少了可能误判高,理论5~10个之间,工程里用3~5个,具体多少可以视需求而定。
代码 :
[cpp]
#include <cstdlib>
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <vector>
#include <stddef.h>
#include <memory.h>
#define BLOOM (1024UL*1024UL*1024UL) // 1G
#define HASH_RESULT 3
typedef unsigned char BloomFilter;
typedef struct __hash_result {
size_t N; // how many result
size_t result[0];
}HashResult;
/* Brian Kernighan & Dennis Ritchie hashfunction , used in Java */
size_t BKDR_hash(const char* str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++) {
hash = hash * 131 + ch;
}
return hash;
}
/* Unix System Hashfunction , also used in Microsoft's hash_map */
size_t FNV_hash(const char* str)
{
if(!*str)
return 0;
register size_t hash = 2166136261;
while (size_t ch = (size_t)*str++) {
hash *= 16777619;
hash ^= ch;
}
return hash;
}
/* Donald
补充:软件开发 , C++ ,