唐茶字节社与Python的故事(I)
万历年间 小太阳先森 先是下载了唐茶的App 书生意气 勤于读书 苦于没官府白花花的银两 然先生习得一手好python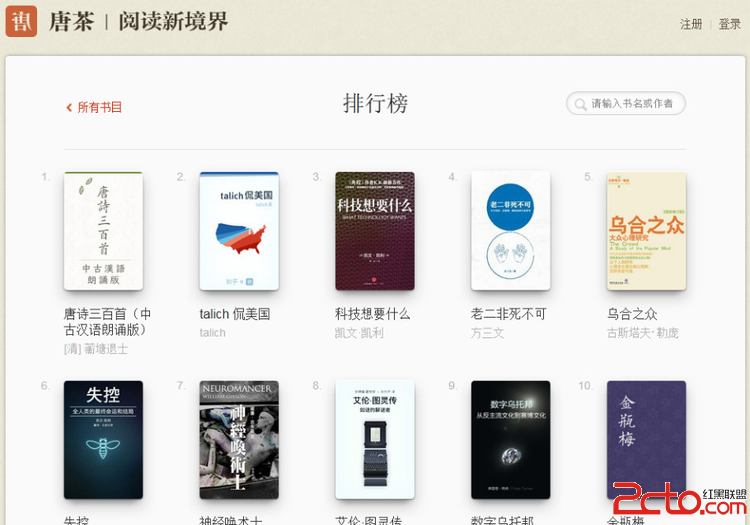
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author :insun
import urllib2
import re
#获得电子书列表,抓取 id,link,thumb_cover,title,author
def get_booklist():
url = 'http://www.tangcha.tc/books/top'
html = urllib2.urlopen(url).read()
reg = re.compile(r'<li class="book-cell">.+?<span>(.*?).</span>'+
'.+?<a href="(.*?)" class="cell-item boxable">'+
'.+?<img.+?src="(.*?)" />.+?</figure>'+
'.+?<p class="book-title">(.*?)</p>'+
'.+?<p class="book-author">(.*?)</p>',re.S)
groups = re.findall(reg,html)
return groups
#获取电子书详细信息,抓取cover,title,author,publisher,douban_rate,content,author_intro
def get_bookdetail(href):
detailurl = 'http://www.tangcha.tc' + href
detailhtml = urllib2.urlopen(detailurl).read()
if re.search('book-publisher book-info-entry',detailhtml) != None:
publish = '.+?<p class="book-publisher book-info-entry">.+?<a .+?>(.*?)</a>.+?</p>.+?<p class="book-device">.+?'
else:
publish = '(.*?)<p class="book-device">'
if re.search('douban-rating-number',detailhtml) != None:
douban = '.+?<div class="douban-rating-number">(.*?)</div></div></a>'
description = '(.*?)<div class=".+?">'
else:
douban = '(.*?)'
description = '.+?<section id="book-description">(.*?)<div class=".+?">'
dreg = re.compile(r'<figure class="book-cover">.+?<img alt=".+?" src="(.*?)" />.+?</figure>'+
'.+?<p class="book-title">(.*?)</p>'+
'.+?<p class="book-author book-info-entry">.+?<a .+?>(.*?)</a>.+?</p>'+
publish+douban+description,re.S)
dgroups = re.findall(dreg,detailhtml)
return dgroups
for i in get_booklist():
href = i[1]
details = get_bookdetail(href)
print details[0]
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author :insun
import urllib
import urllib2,sys
import re
import pymongo
import os
db = pymongo.Connection().test
if(os.path.exists('thumb')==False):
os.mkdir('thumb')
if(os.path.exists('cover')==False):
os.mkdir('cover')
#新书上架 http://www.tangcha.tc/books/latest 82*5 = 410
#排行榜 http://www.tangcha.tc/books/top 410
#本期推荐 http://www.tangcha.tc/books/recommendation
#获得电子书列表,抓取 id,link,thumb_cover,title,author
def get_booklist():
url = 'http://www.tangcha.tc/books/top'
html = urllib2.urlopen(url).read()
reg = re.compile(r'<li class="book-cell">.+?<span>(.*?).</span>'+
'.+?<a href="(.*?)" class="cell-item boxable">'+
'.+?<img.+?src="(.*?)" />.+?</figure>'+
'.+?<p class="book-title">(.*?)</p>'+
'.+?<p class="book-author">(.*?)</p>',re.S)
groups = re.findall(reg,html)
return groups
#获取电子书详细信息,抓取cover,title,author,publisher,douban_rate,content,author_intro
def get_bookdetail(href):
detailurl = 'http://www.tangcha.tc' + href
detailhtml = urllib2.urlopen(detailurl).read()
if re.search('book-publisher book-info-entry',detailhtml) != None:
publish = '.+?<p class="book-publisher book-info-entry">.+?<a .+?>(.*?)</a>.+?</p>.+?<p class="book-device">.+?'
else:
publish = '(.*?)<p class="book-device">'
if re.search('douban-rating-number',detailhtml) != None:
douban = '.+?<div class="douban-rating-number">(.*?)</div></div></a>'
description = '(.*?)<div class=".+?">'
else:
douban = '(.*?)'
descriptio
补充:Web开发 , Python ,



- 更多python疑问解答:
- python 把图片转换成base64代码 python 把base64代码转换成图片
- 利用python进行网络图片下载 python批量下载远程图片
- 记录Python读写文件的代码和方法
- Python如何把图片转为Base64字符串
- python用requests.get批量下载网络远程图片的代码
- 疑难杂症,关于python与C#输出重定向
- 最近写的一个软件,对照下c#,c++,DELPHI,VB,易语言,PYTHON,PHP等执行效率
- 利用C#4.0调用IronPython脚本
- bat 执行定时python 打开url 谁搞过,帮忙看一下语句有什么问题
- 求助!在线等!python调用C#的.dll库
- Python 快速界面开发?求IDE和资料..中文的最好
- python如何读取XML文件中的
- .NET运行IronPython脚本错误
- 新手之前对编程无概念现在想转这行,想尽快入门,java ,python,.net、php、C之间如
- 新手之前对编程无概念现在想转这行,想尽快入门,java ,python,.net、php、C之间如