Python网络编程测试-Parser初探
HTML或者XHTML可能是每个使用电脑的人最常接触的编程语言,在感叹google , bing , baidu等等(顺便加上我老师的安图搜索)搜索引擎搜索功能的强大时,有没有想过自己编写一个呢?
下面的code是测试而已,不论从“表面“或者从”内在“来说都存在一大堆问题,仅供同学们参考
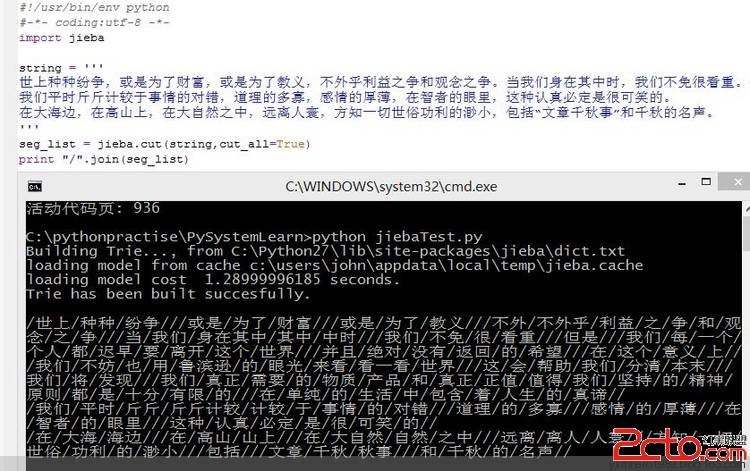
code实现了从网页信息中获取图片URL的功能
[python]
class ImgParser(HTMLParser):
def __init__(self):
self.tag = ''
self.attrs = ''
self.readingtitle = False
HTMLParser.__init__(self)
def handle_starttag(self , tag , attrs):
if tag == 'img':
self.readingtitle = True
for name , value in attrs:
print(value)
def handle_data(self , data):
if self.readingtitle == True:
self.tag += data
def handle_endtag(self , tag):
if tag == 'img':
self.readingtitle = False
这里HTMLParser模块还是要说一下的(很有意思的模块):
HTMLParser本身是不提供太多功能的,如果需要解析HTML的话,就继承HTMLParser就可以了。对于一些特定的功能函数,类似于C++中的virtual函数(个人理解)来定义对HTML中的Element进行细微的处理:
handle_starttag(self , tag , attrs): 处理开始标签内的信息<tag attrs = "...">data</tag>,其中attrs(属性)将会以存储在list中
handle_endtag(self , tag):处理结束标签内的信息<tag attrs = "...">data</tag>
handle_data(self , data):处理元素数据信息<tag attrs = "...">data</tag>
测试的test.html:
[html]
<!--Basic Title parsing-->
<HTML>
<HEAD>
<TITLE>
Document Title
</TITLE>
</HEAD>
<BODY id="1" name="this is a body">
<img id = "1" src = "here is the image data" >hoho</img>
here is the test
</BODY>
</HTML>
当然一个好的parser(爬虫谐音么???是音译过来的???牛人指教)不会三下两下就完成的,了解解析机制之后,要做的就是虚心学习,交流和努力了
摘自 FishinLab的专栏
补充:Web开发 , Python ,