Muduo网络编程示例之五: 测量两台机器的网络延迟
测量 RTT 的办法很简单:
host A 发一条消息给 host B,其中包含 host A 发送消息的本地时间
host B 收到之后立刻把消息 echo 回 host A
host A 收到消息之后,用当前时间减去消息中的时间就得到了 RTT。
NTP 协议的工作原理与之类似,不过,除了测量 RTT,NTP 还需要知道两台机器之间的时间差 (clock offset),这样才能校准时间。
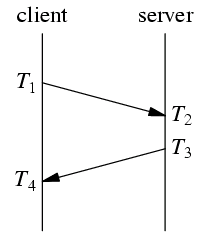
以上是 NTP 协议收发消息的协议,RTT = (T4-T1) – (T3-T2),时间差 = ((T4+T1)-(T2+T3))/2。NTP 的要求是往返路径上的单程延迟要尽量相等,这样才能减少系统误差。偶然误差由单程延迟的不确定性决定。
在我设计的 roundtrip 示例程序中,协议有所简化:
简化之后的协议少取一次时间,因为 server 收到消息之后立刻发送回 client,耗时很少(若干微秒),基本不影响最终结果。
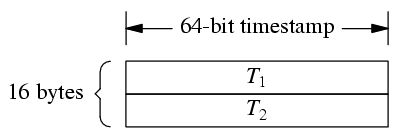
我设计的消息格式是 16 字节定长消息:
T1 和 T2 都是 muduo::Timestamp,一个 int64_t,表示从 Epoch 到现在的微秒数。
为了让消息的单程往返时间接近,server 和 client 发送的消息都是 16 bytes,这样做到对称。
由于是定长消息,可以不必使用 codec,在 message callback 中直接用
while (buffer->readableBytes() >= frameLen) { ... } 就能 decode。
请读者思考,如果把 while 换成 if 会有什么后果?
client 程序以 200ms 为间隔发送消息,在收到消息之后打印 RTT 和 clock offset。一次运作实例如下:
这个例子中,client 和 server 的时钟不是完全对准的,server 的时间快了 850 us,用 roundtrip 程序能测量出这个时间差。有了这个时间差就能校正分布式系统中测量得到的消息延迟。
比方说以上图为例,server 在它本地 1.235000 时刻发送了一条消息,client 在它本地 1.234300 收到这条消息,直接计算的话延迟是 –700us。这个结果肯定是错的,因为 server 和 client 不在一个时钟域(这是数字电路中的概念),它们的时间直接相减无意义。如果我们已经测量得到 server 比 client 快 850us,那么做用这个数据一次校正: -700+850 = 150us,这个结果就比较符合实际了。当然,在实际应用中,clock offset 要经过一个低通滤波才能使用,不然偶然性太大。
请读者思考,为什么不能直接以 RTT/2 作为两天机器之间收发消息的单程延迟?
这个程序在局域网中使用没有问题,如果在广域网上使用,而且 RTT 大于 200ms,那么受 Nagle 算法影响,测量结果是错误的(具体分析留作练习,这能测试对 Nagle 的理解),这时候我们需要设置 TCP_NODELAY 参数,让程序在广域网上也能正常工作。
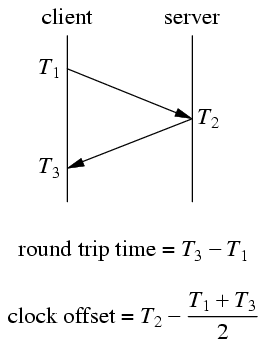
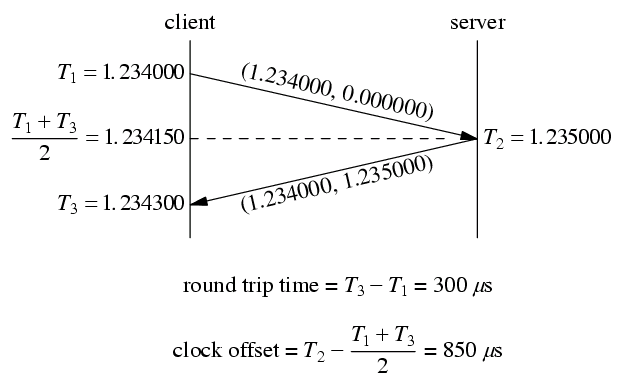
补充:软件开发 , C语言 ,