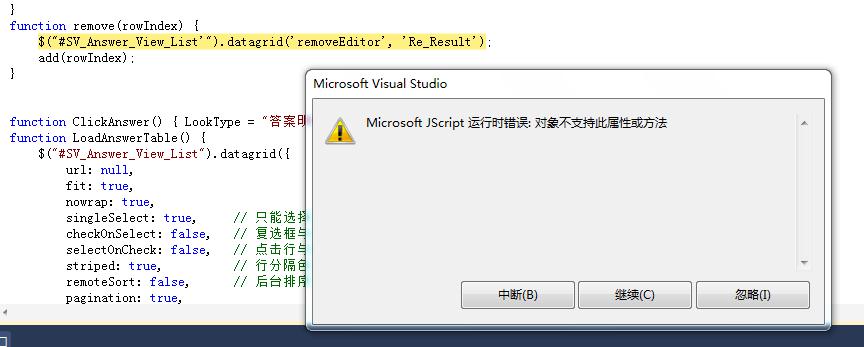
C#初学者,有关于采集后过滤的问题.在线等...
string strHtmlCode = "http://sports.sina.com.cn/k/2008-06-10/12133713169.shtml";GetHtmlClass.GetRemoteObj gr = new GetHtmlClass.GetRemoteObj();
temp = gr.GetRemoteHtmlCode(strHtmlCode);
string Content = Sprider.GetHtmlContent.GetContent(temp.ToLower().Trim().Replace("\r\n", ""), "<!--正文内容开始-->", "<!--正文内容结束-->");//获取正文
Content = Regex.Replace(Content, @"\<a href(?<a>[^>]*)\>", "", RegexOptions.IgnoreCase);//过滤正文超连接
Content = Regex.Replace(Content, @"\<!--(?<a>[^>]*)\>", "", RegexOptions.IgnoreCase);//过滤<!--></!-->
Content = Content.Replace("</a>", "");
Content = Content.Replace("<-->", "");
Label1.Text = Content;
要过滤采集过来的这个页里最下面的这些内容..请高手指教,,,
新浪网关于版权的最新声明</p-->
声明:新浪网独家稿件,转载请注明出处。 </div> </span><br />
<span id="Label2">http://sports.sina.com.cn/k/2008-06-10/12133713170.shtml</span>
<br />
<span id="Label3">齐小侠:湖人究竟怎么了?总决赛为何迎来反易做图 src=http://i1.sinaimg.cn/ty/k/2008-06-10/U687P6T12D3713169F44DT20080610121359.jpg </span></div>
这一段如何过滤啊...找了一天没找到答案..
--------------------编程问答-------------------- 利用正则过滤掉HTML标签啊
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
补充:.NET技术 , C#